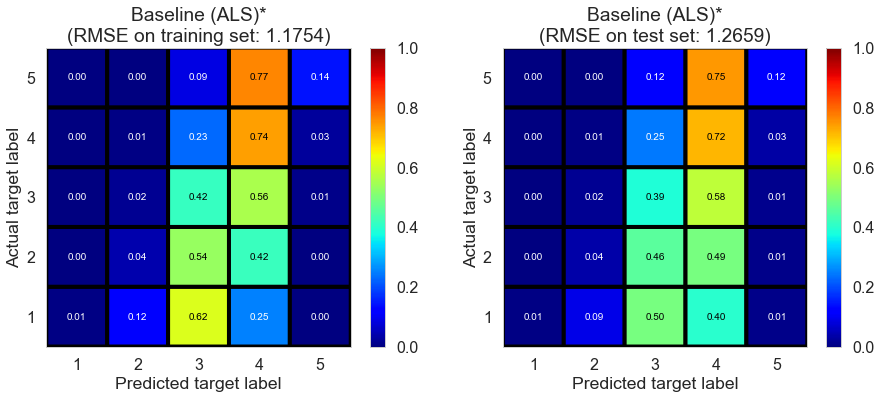
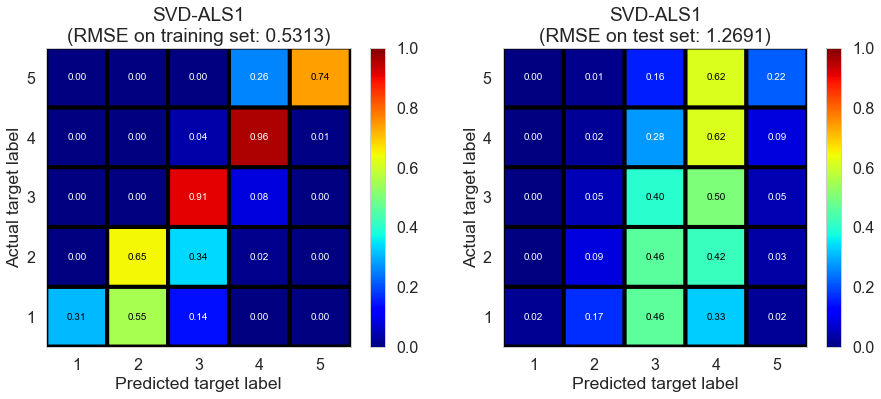
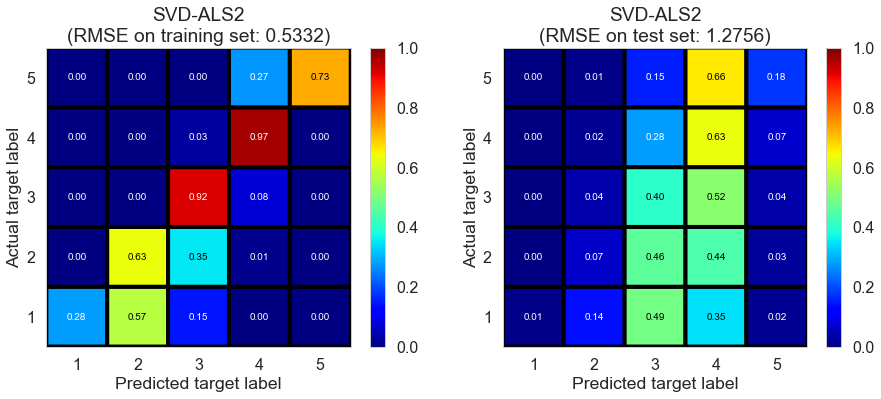
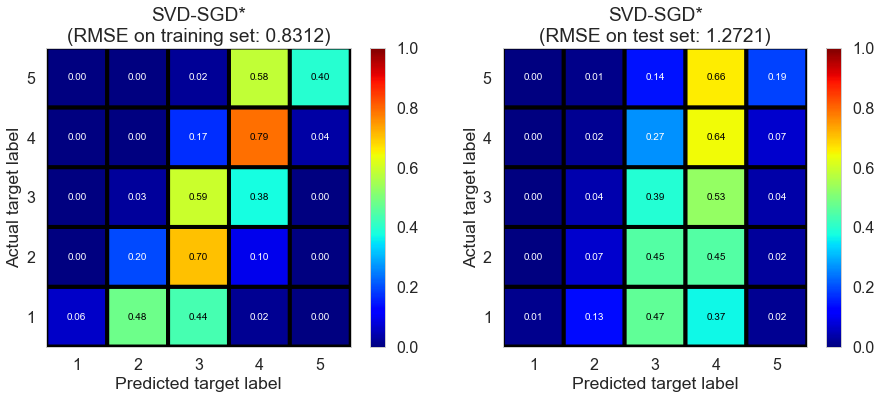
Results
Contents
- Methods
- Results
- Champaign (20571 reviews, 878 restaurants, 8451 users)
- Cleveland (75932 reviews, 2500 restaurants, 30131 users)
- Pittsburgh (143682 reviews, 4745 restaurants, 46179 users)
- Toronto (331407 reviews, 12118 restaurants, 77506 users)
- Las_Vegas (1280896 reviews, 20434 restaurants, 429363 users)
- Full (4166778 reviews, 131025 restaurants, 1117891 users)
Methods
We benchmarked the base estimators and ensemble estimators in 6 datasets of different sizes. In each dataset, we randomly split the reviews into 3 sets: a training set (60%), a cross-validation set (16%) and a test set (24%). We train base estimators on the training set, and test on the test set; cross-validation set is used for the training of ensemble estimators. All experiments are run on a desktop with Inter Xeon CPU 3.10 GHz, 256 GB RAM.
Results
Champaign (20571 reviews, 878 restaurants, 8451 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Mode estimator | 0.0000 | 1.9995 | 2.0258 | -0.9501 | -0.9500 |
| Normal predictor* | 0.0870 | 1.8825 | 1.8821 | -0.7286 | -0.6833 |
| Baseline (mean) | 0.0190 | 0.9485 | 1.4648 | 0.5612 | -0.0195 |
| Baseline (regression) | 0.0350 | 1.0481 | 1.3032 | 0.4642 | 0.1930 |
| Baseline (ALS)* | 0.0570 | 1.1981 | 1.3200 | 0.2998 | 0.1721 |
| KNN (basic)* | 0.9841 | 0.4328 | 1.4642 | 0.9086 | -0.0187 |
| KNN (with means)* | 1.2851 | 0.5898 | 1.5310 | 0.8303 | -0.1138 |
| KNN (baseline)* | 1.0201 | 0.4175 | 1.3718 | 0.9150 | 0.1058 |
| SVD-ALS1 | 12.2077 | 0.6747 | 1.3064 | 0.7780 | 0.1891 |
| SVD-ALS2 | 12.9087 | 0.6764 | 1.3092 | 0.7768 | 0.1855 |
| SVD-SGD* | 1.0721 | 0.8929 | 1.3173 | 0.6111 | 0.1754 |
| SVD++-SGD* | 3.2642 | 0.9285 | 1.3220 | 0.5795 | 0.1695 |
| NMF-SGD* | 1.1601 | 0.2485 | 1.5226 | 0.9699 | -0.1016 |
| Slope one* | 0.1530 | 0.3545 | 1.5546 | 0.9387 | -0.1484 |
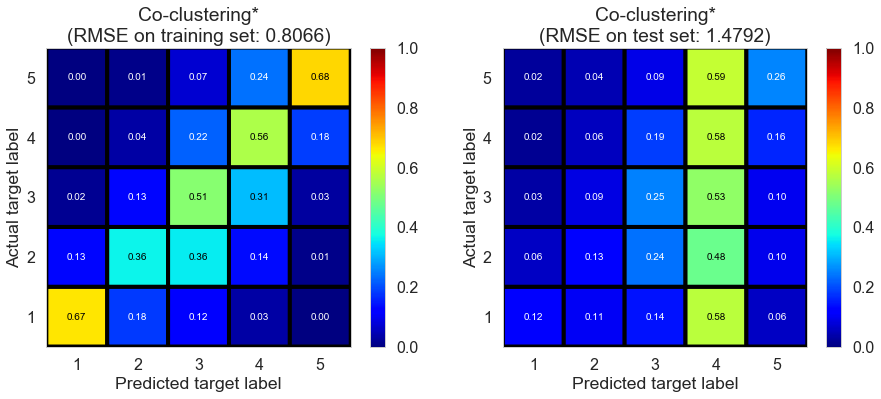
| Co-clustering* | 1.2161 | 0.8066 | 1.4792 | 0.6826 | -0.0398 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
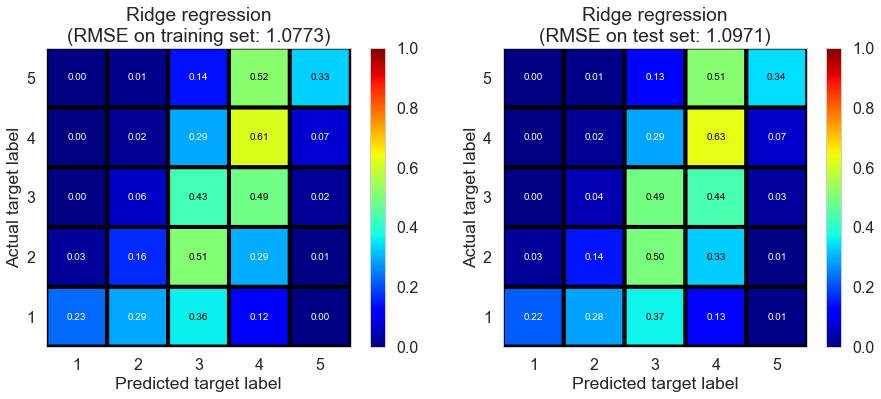
| Ridge regression | 0.0690 | 1.0773 | 1.0971 | 0.4339 | 0.4280 |
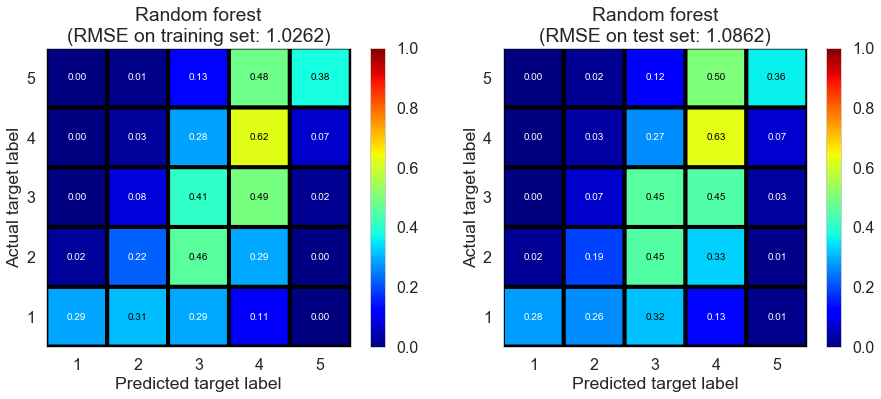
| Random forest | 1.0951 | 1.0262 | 1.0862 | 0.4864 | 0.4394 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
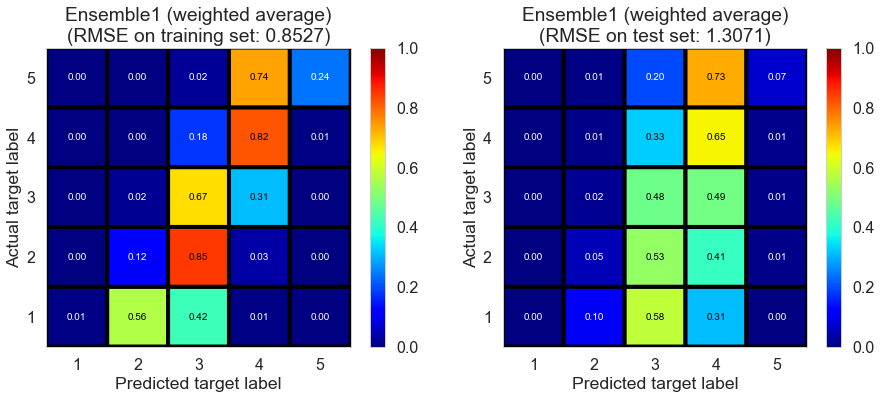
| Ensemble1 (weighted average) | 0.000 | 0.8527 | 1.3071 | 0.6454 | 0.1882 |
| Ensemble1 (Ridge regression) | 0.011 | 1.3268 | 1.3026 | 0.1413 | 0.1937 |
| Ensemble1 (random forest) | 0.220 | 1.0506 | 1.3048 | 0.4617 | 0.1910 |
| Ensemble2 (weighted average) | 0.000 | 0.9007 | 1.1591 | 0.6043 | 0.3616 |
| Ensemble2 (Ridge regression) | 0.004 | 1.2721 | 1.0830 | 0.2107 | 0.4426 |
| Ensemble2 (random forest) | 0.271 | 1.0678 | 1.0847 | 0.4439 | 0.4409 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)
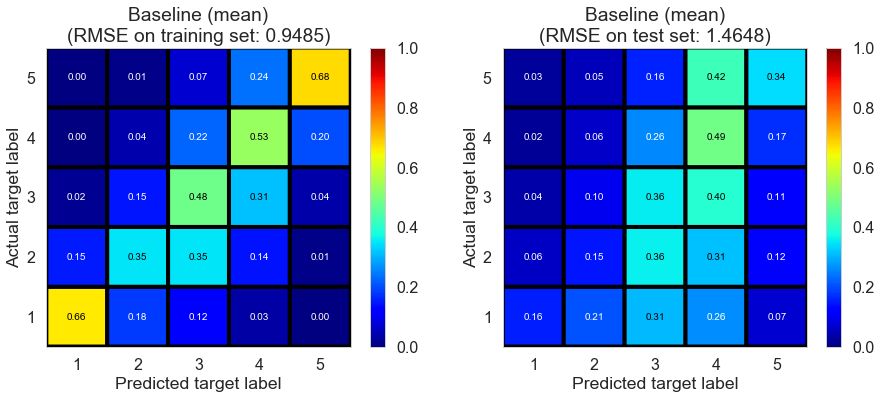
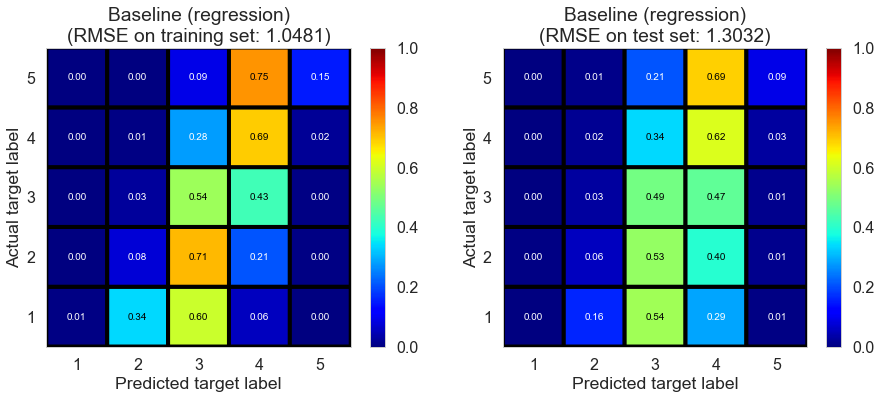
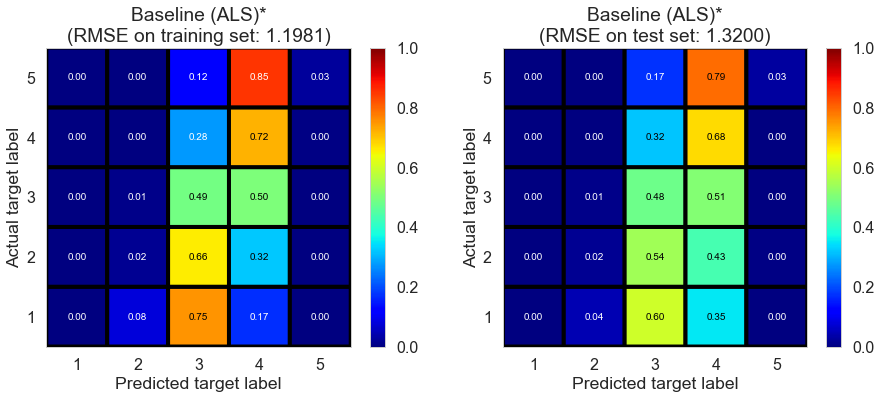
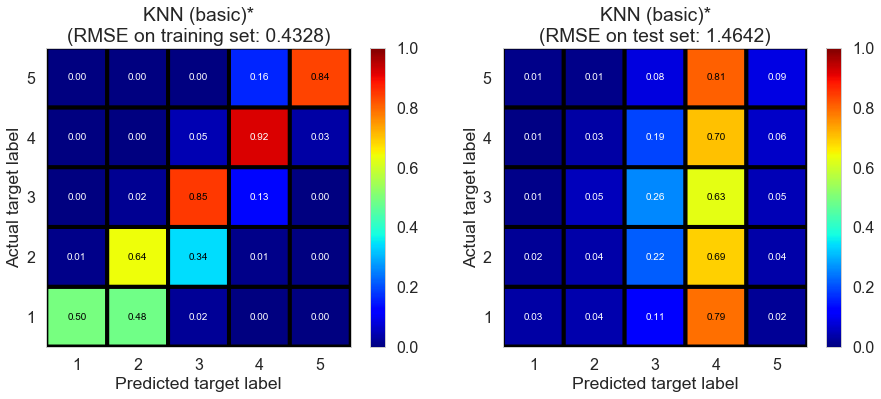
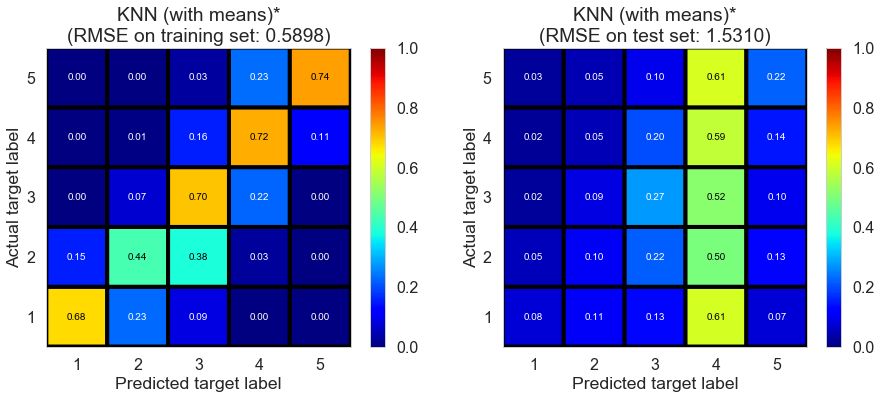
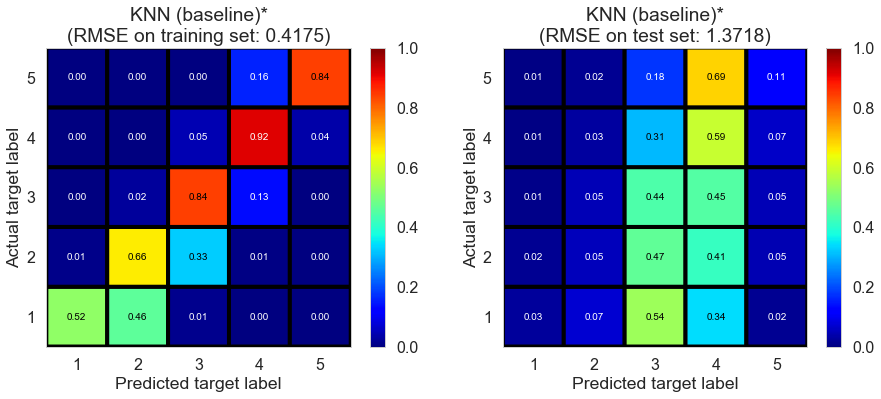
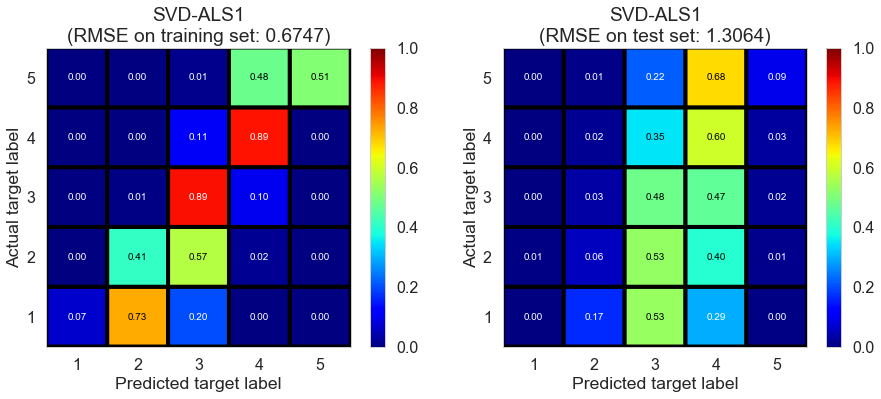
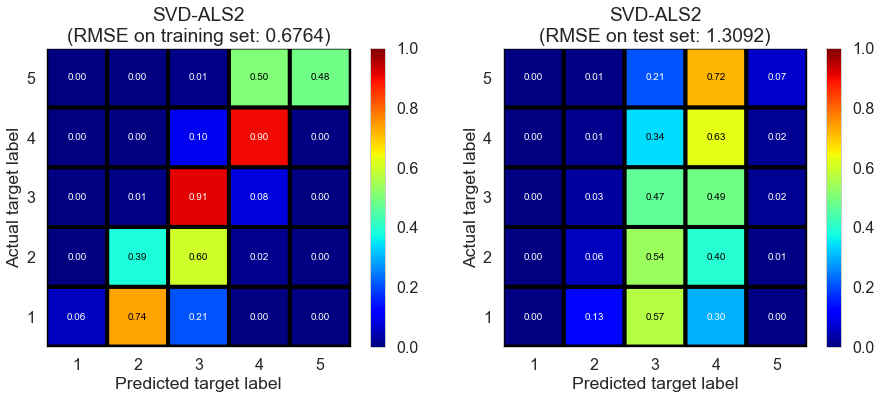
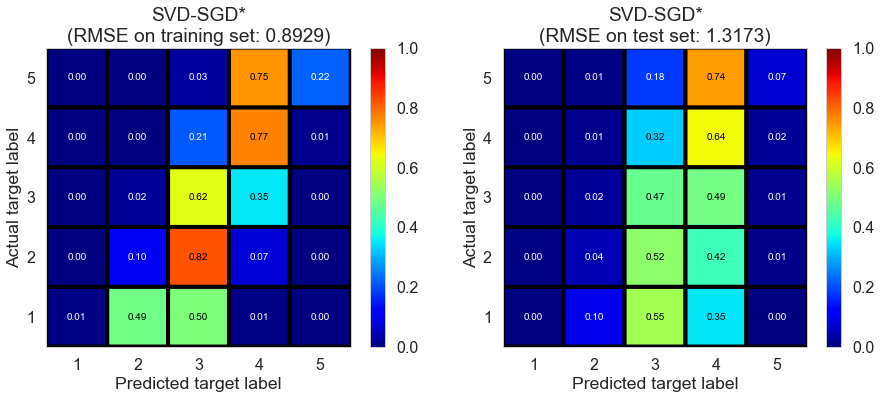
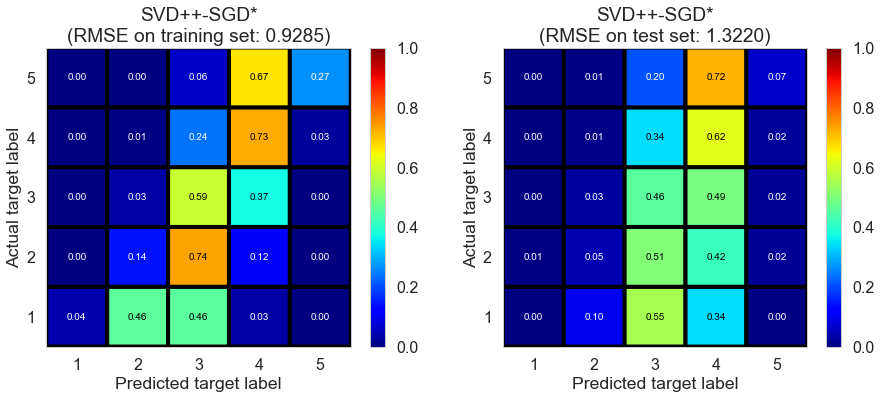
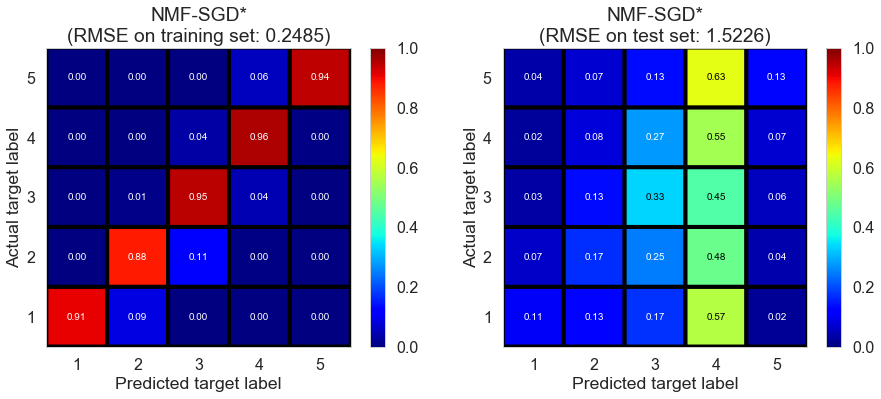
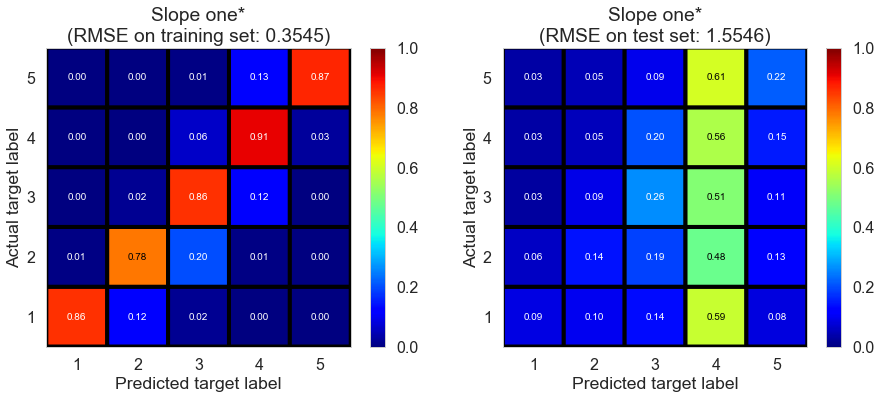
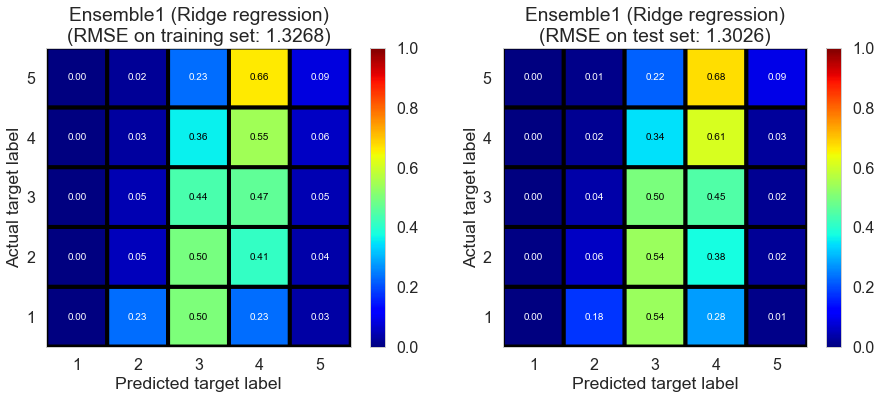
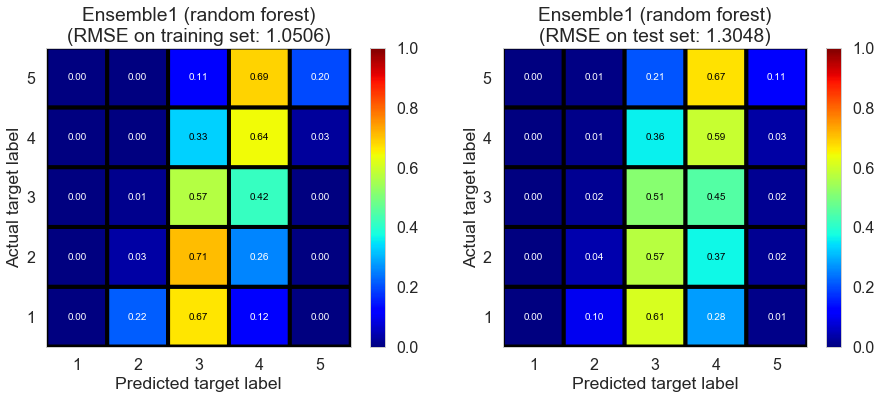
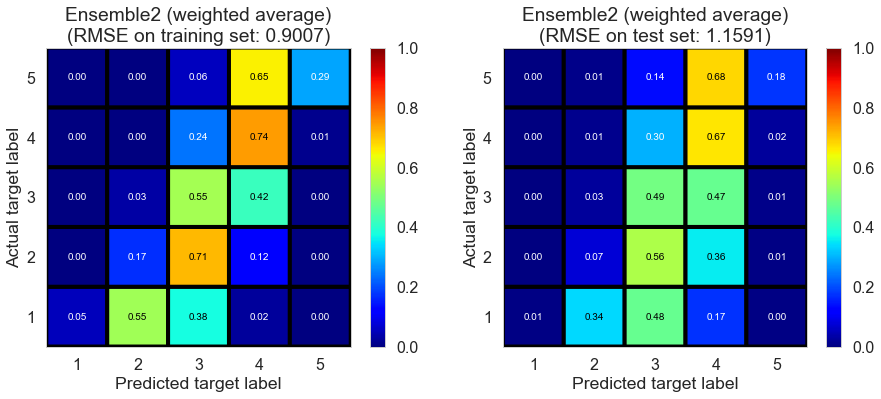
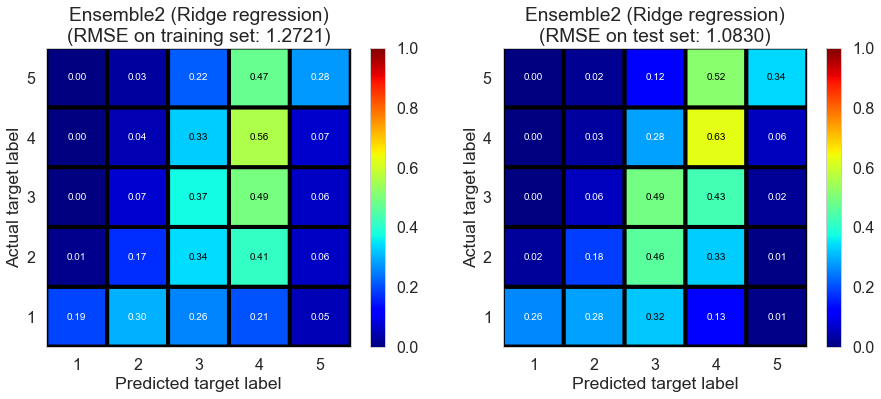
Cleveland (75932 reviews, 2500 restaurants, 30131 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
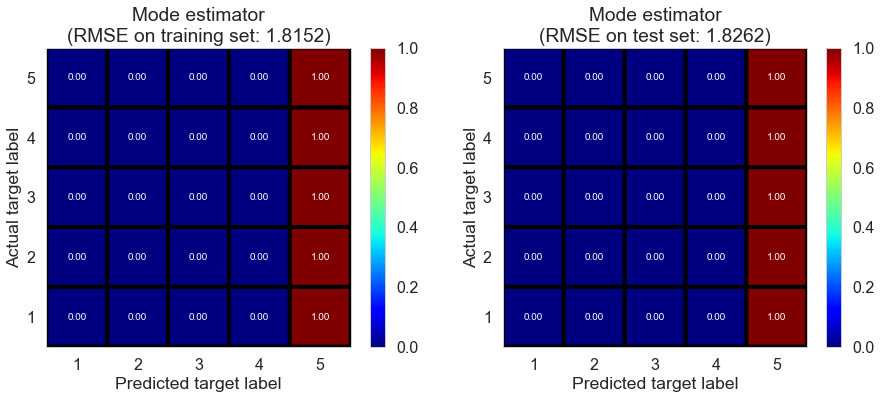
| Mode estimator | 0.0000 | 1.8152 | 1.8262 | -0.8226 | -0.8371 |
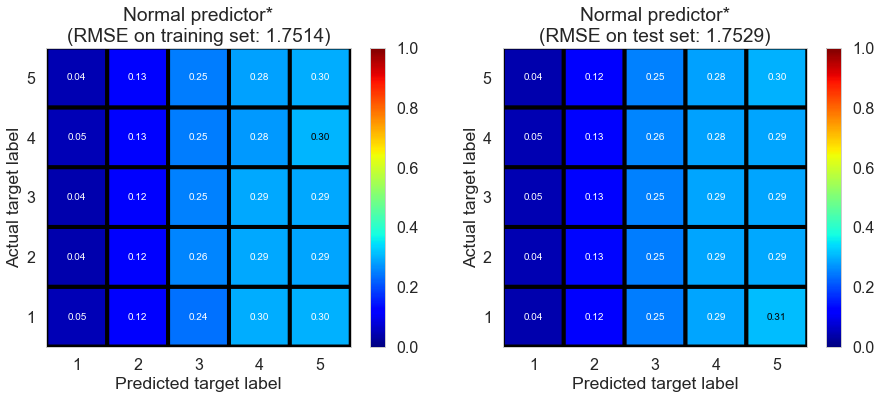
| Normal predictor* | 0.2250 | 1.7514 | 1.7529 | -0.6968 | -0.6926 |
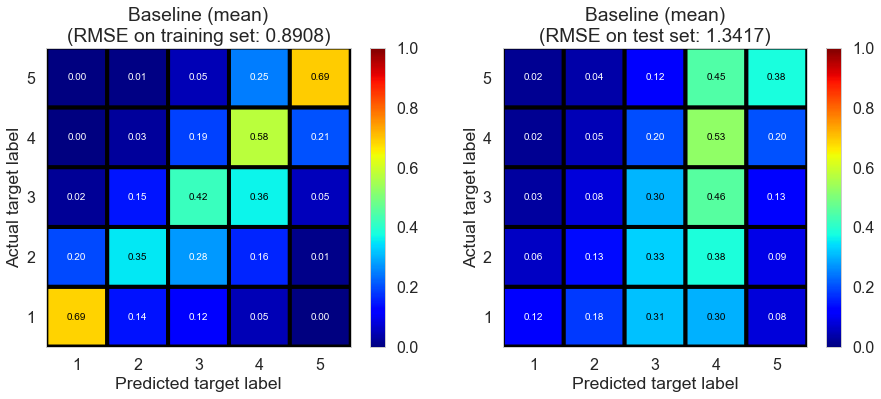
| Baseline (mean) | 0.0550 | 0.8908 | 1.3417 | 0.5610 | 0.0084 |
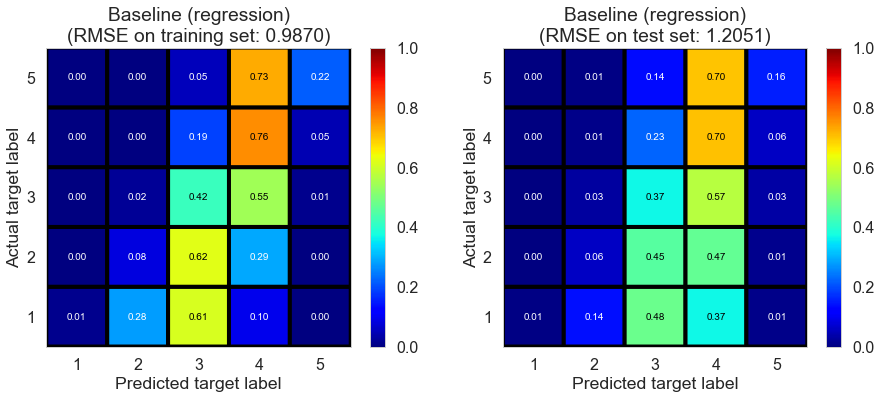
| Baseline (regression) | 0.1110 | 0.9870 | 1.2051 | 0.4611 | 0.2000 |
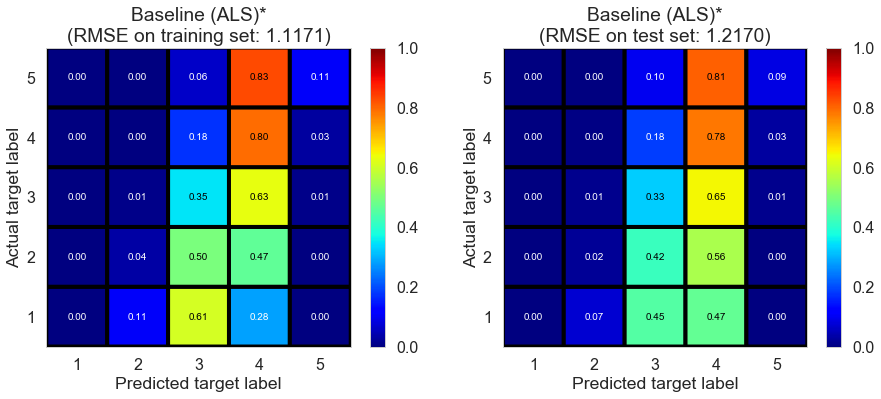
| Baseline (ALS)* | 0.2790 | 1.1171 | 1.2170 | 0.3097 | 0.1841 |
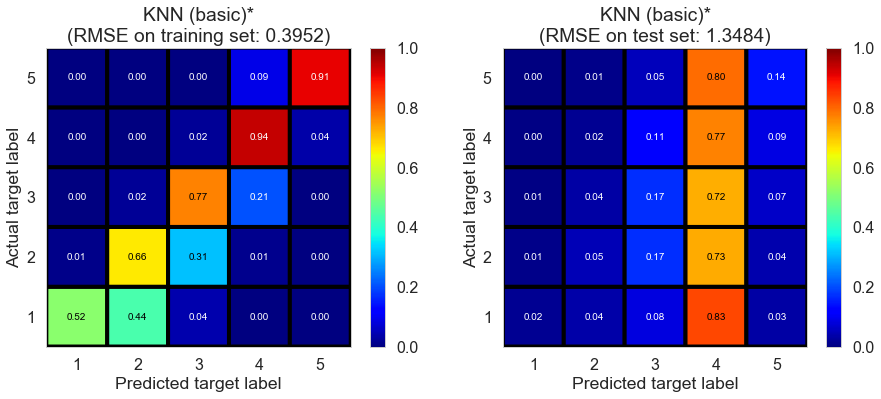
| KNN (basic)* | 13.4688 | 0.3952 | 1.3484 | 0.9136 | -0.0016 |
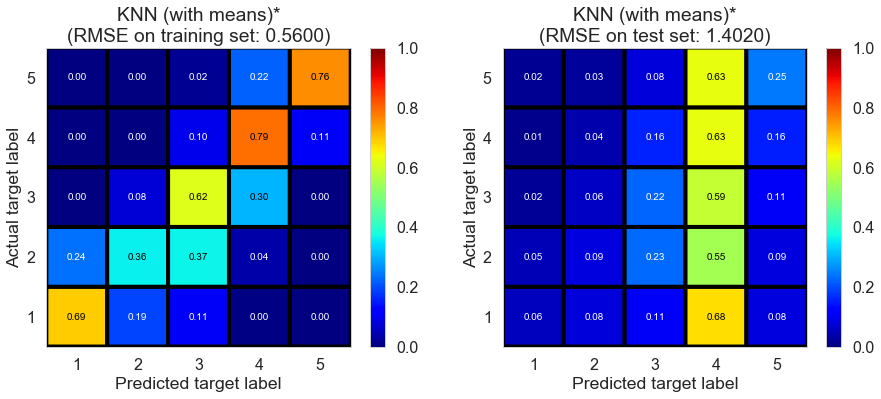
| KNN (with means)* | 14.3168 | 0.5600 | 1.4020 | 0.8265 | -0.0829 |
| KNN (baseline)* | 13.0127 | 0.3837 | 1.2612 | 0.9186 | 0.1237 |
| SVD-ALS1 | 41.9954 | 0.5721 | 1.2095 | 0.8190 | 0.1941 |
| SVD-ALS2 | 44.2825 | 0.5740 | 1.2121 | 0.8177 | 0.1907 |
| SVD-SGD* | 3.8932 | 0.8239 | 1.2204 | 0.6245 | 0.1796 |
| SVD++-SGD* | 15.5919 | 0.8628 | 1.2232 | 0.5882 | 0.1758 |
| NMF-SGD* | 4.6793 | 0.3102 | 1.3997 | 0.9468 | -0.0793 |
| Slope one* | 0.7920 | 0.3622 | 1.4140 | 0.9274 | -0.1013 |
| Co-clustering* | 4.3442 | 0.7050 | 1.3656 | 0.7251 | -0.0273 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ridge regression | 0.2860 | 1.0195 | 1.0313 | 0.4251 | 0.4141 |
| Random forest | 4.7943 | 0.9929 | 1.0155 | 0.4546 | 0.4320 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ensemble1 (weighted average) | 0.0000 | 0.7559 | 1.2085 | 0.6839 | 0.1955 |
| Ensemble1 (Ridge regression) | 0.0050 | 0.9587 | 1.2040 | 0.4916 | 0.2014 |
| Ensemble1 (random forest) | 0.7260 | 0.9431 | 1.2063 | 0.5080 | 0.1984 |
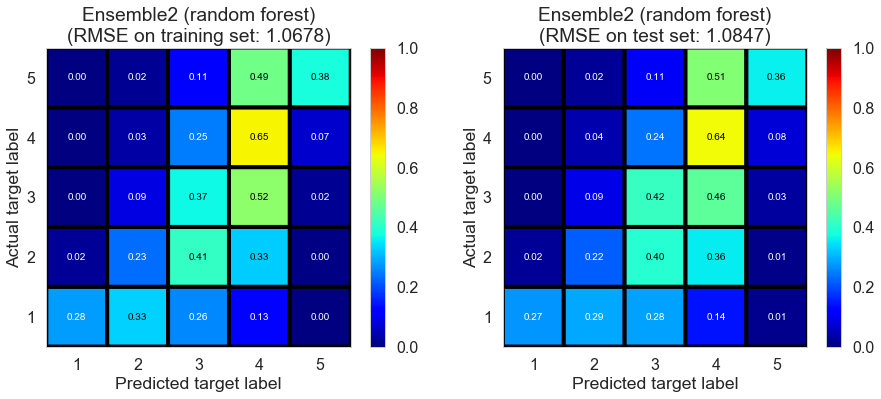
| Ensemble2 (weighted average) | 0.0000 | 0.8214 | 1.0915 | 0.6268 | 0.3437 |
| Ensemble2 (Ridge regression) | 0.0070 | 1.0072 | 1.0141 | 0.4389 | 0.4334 |
| Ensemble2 (random forest) | 0.9471 | 0.9989 | 1.0180 | 0.4480 | 0.4291 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)
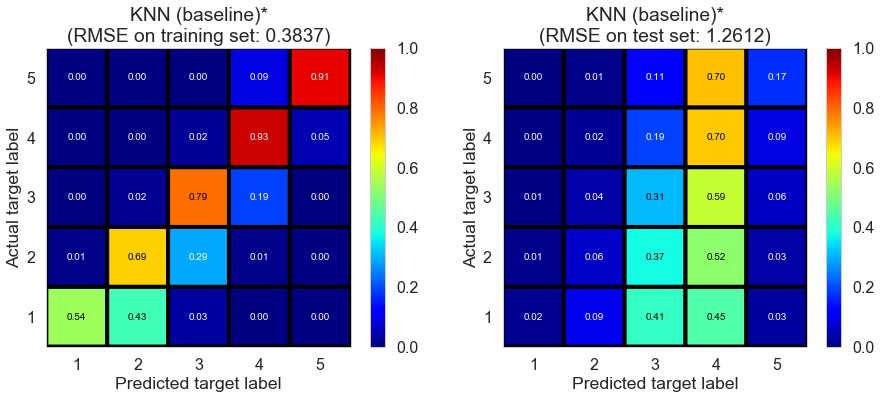
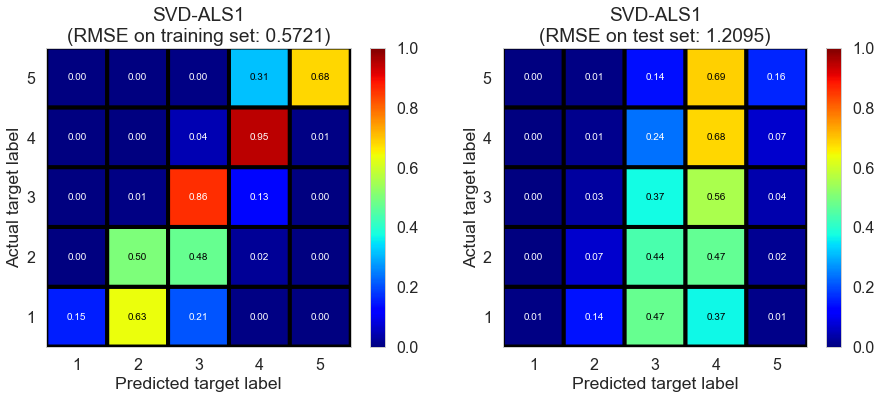
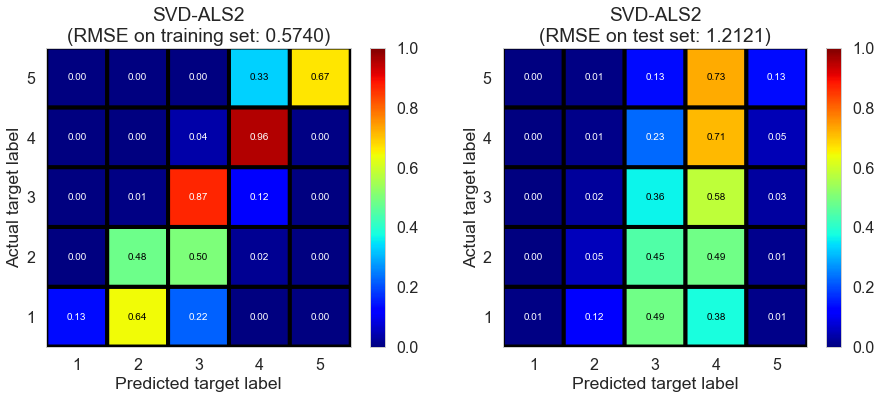
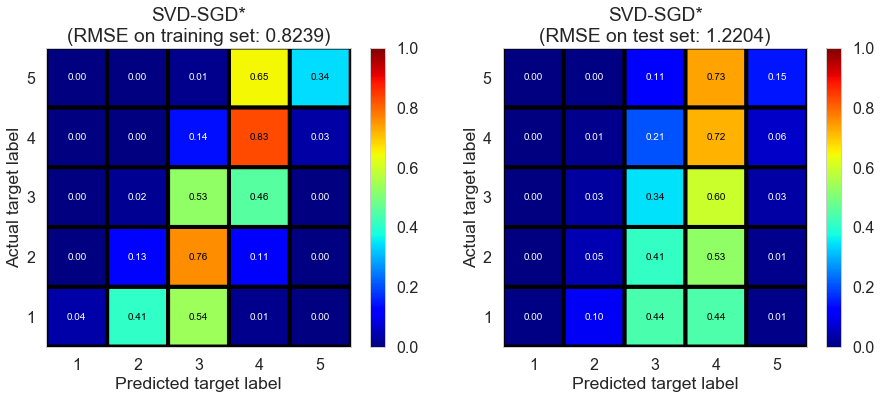
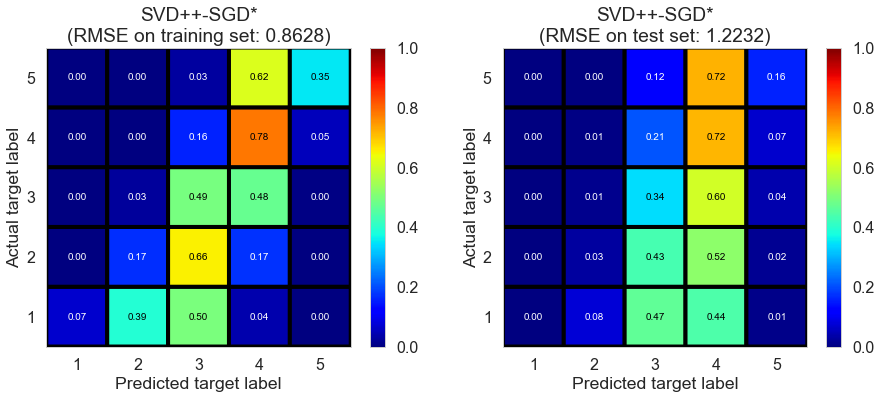
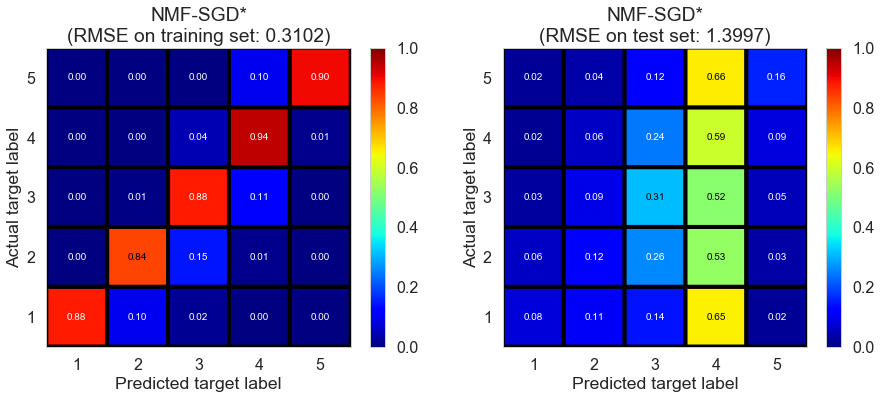
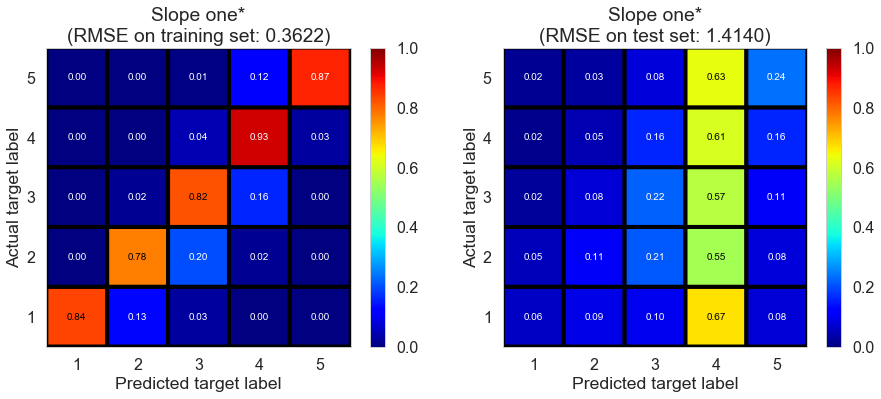
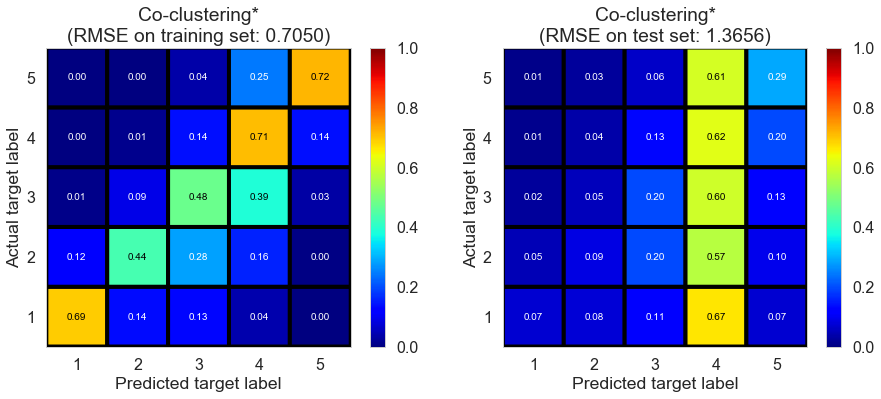
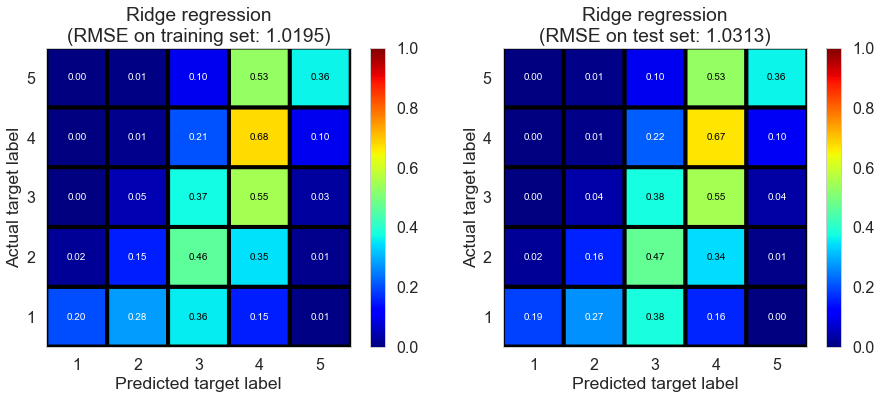
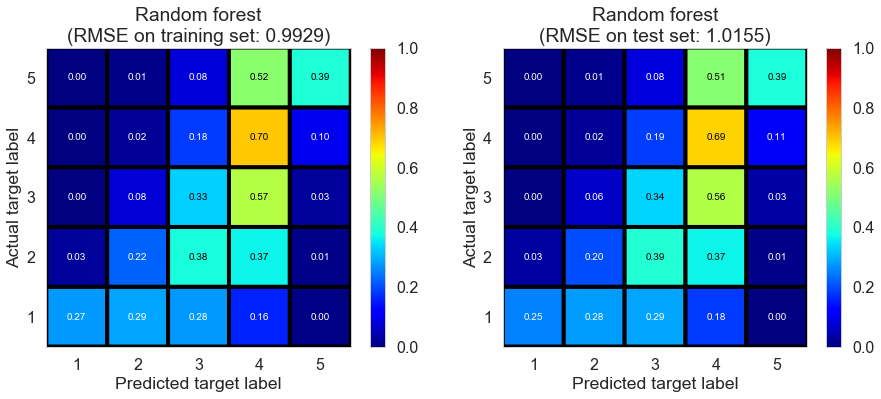
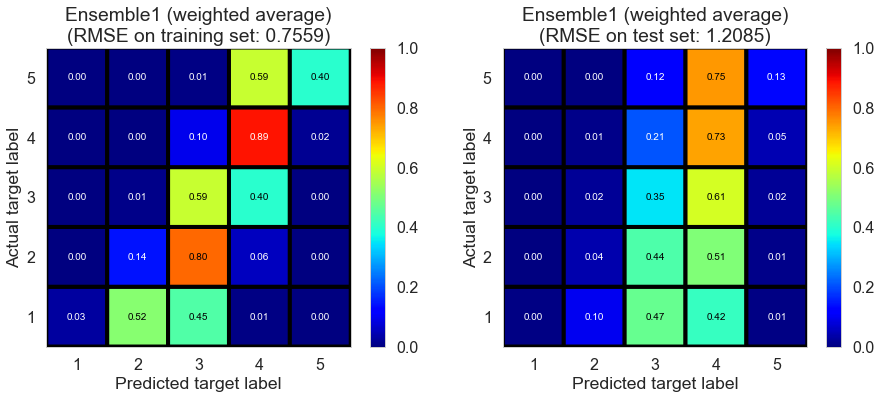
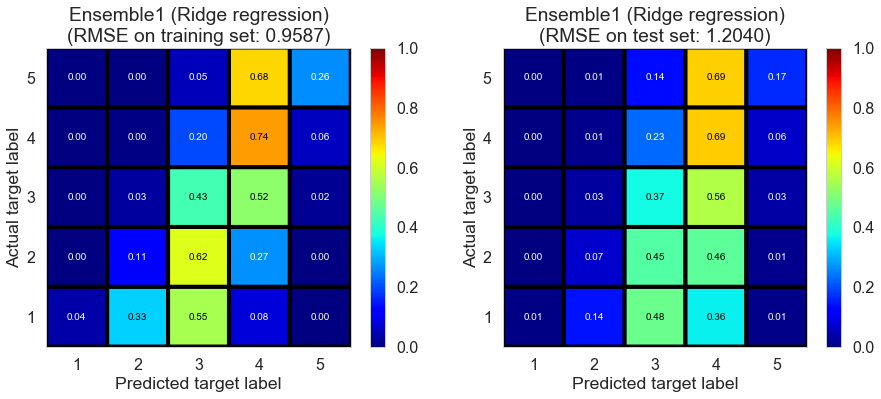
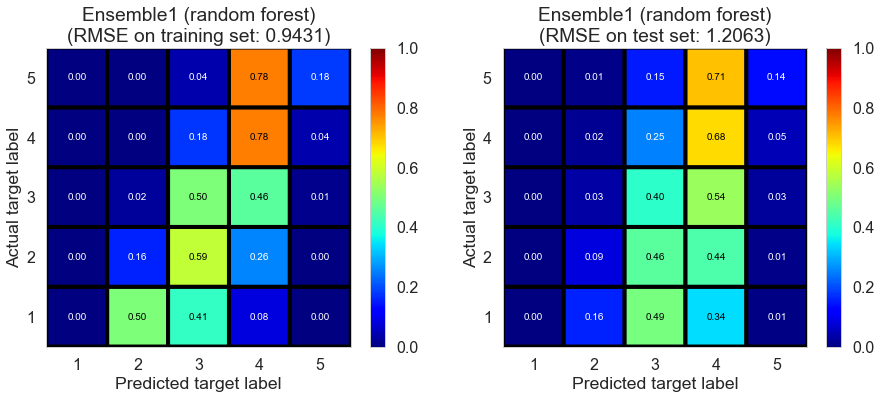
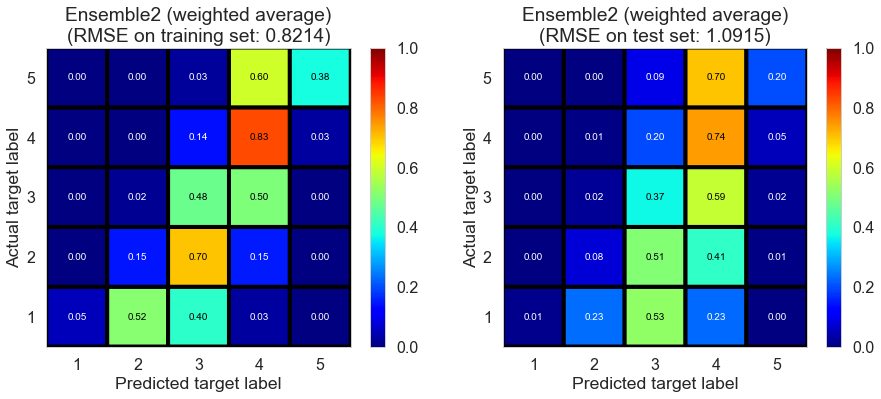
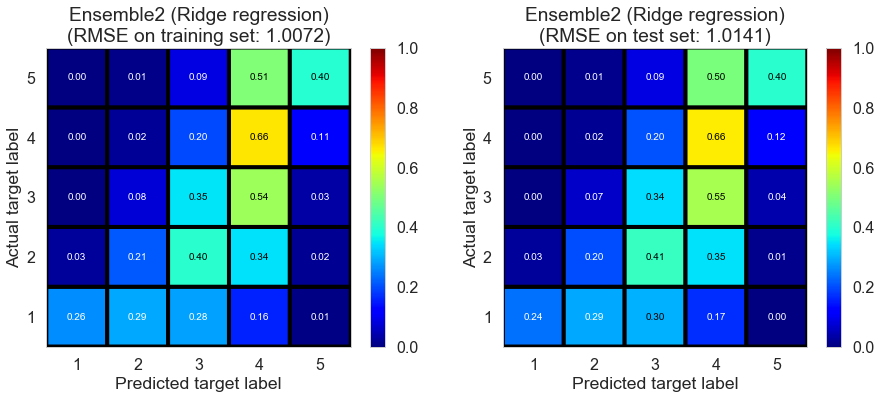
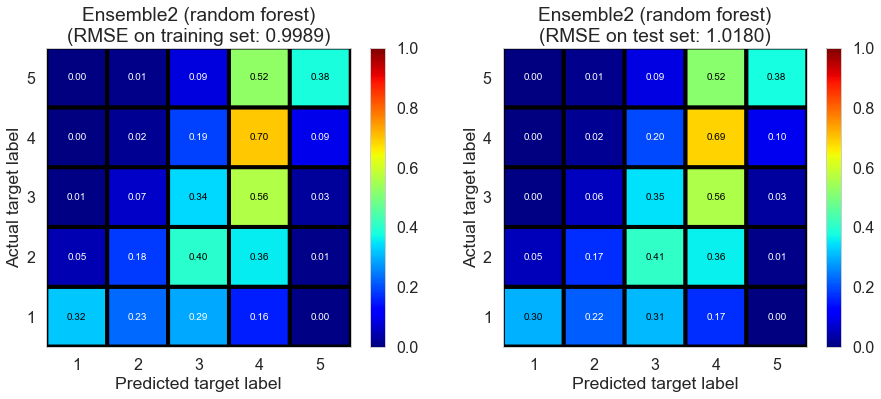
Pittsburgh (143682 reviews, 4745 restaurants, 46179 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
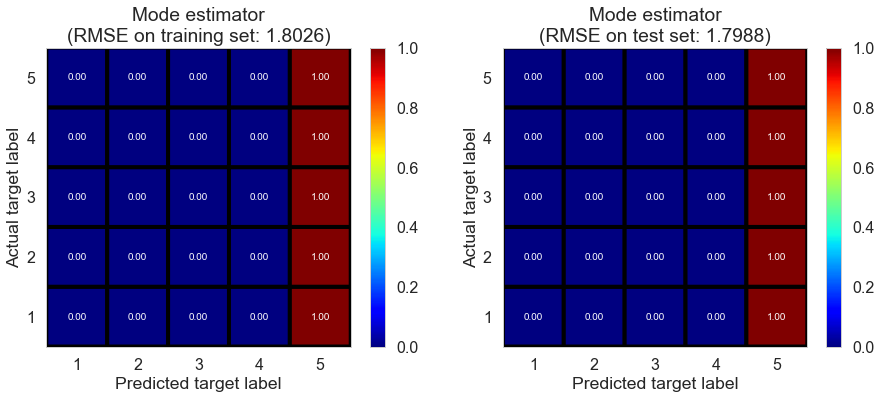
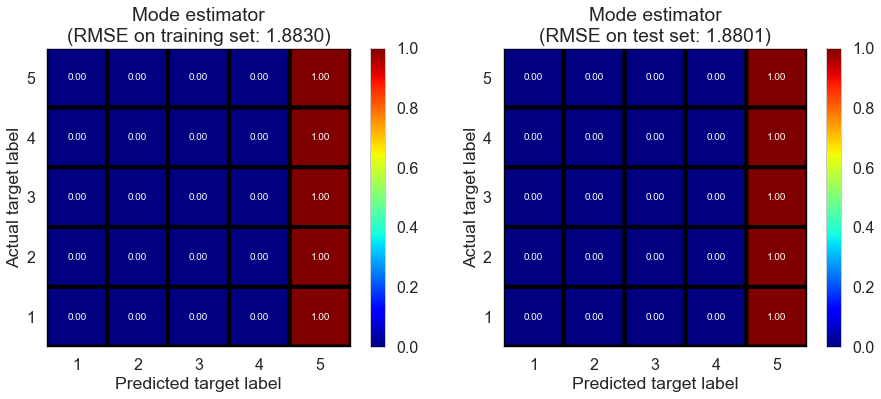
| Mode estimator | 0.0000 | 1.8026 | 1.7988 | -0.8466 | -0.8393 |
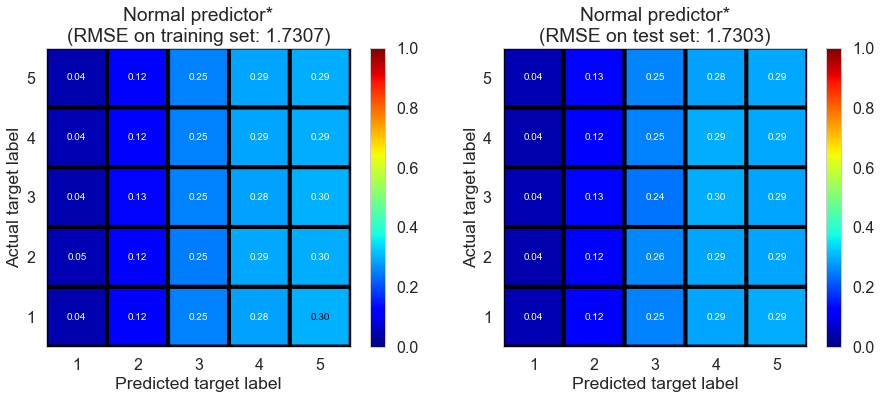
| Normal predictor* | 0.4550 | 1.7307 | 1.7303 | -0.7022 | -0.7017 |
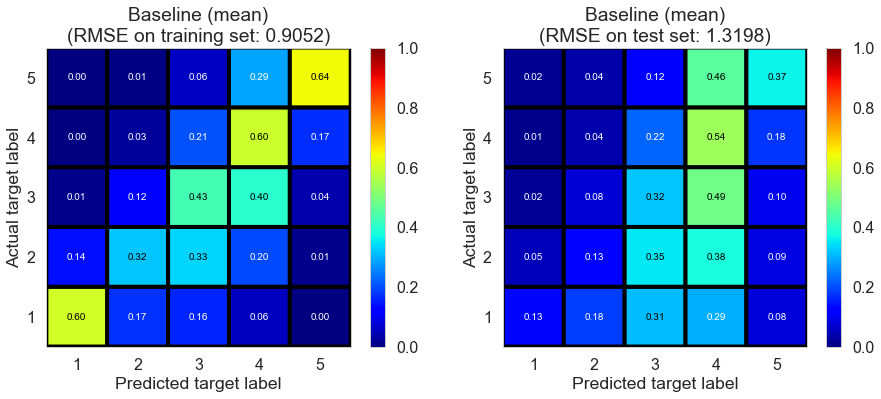
| Baseline (mean) | 0.1020 | 0.9052 | 1.3198 | 0.5343 | 0.0099 |
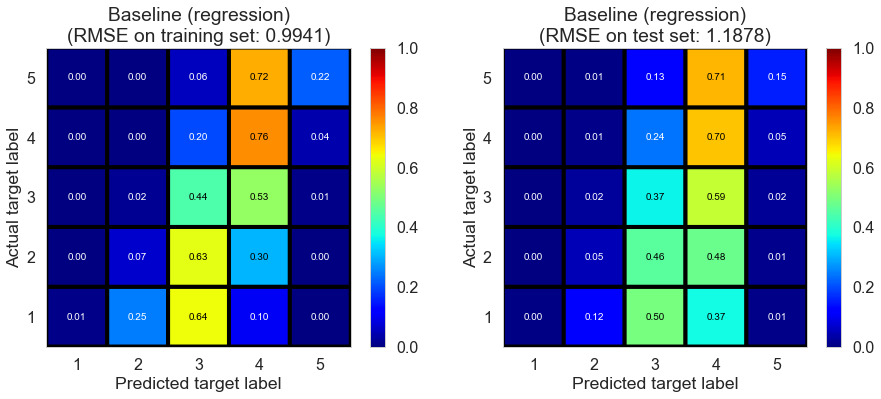
| Baseline (regression) | 0.2000 | 0.9941 | 1.1878 | 0.4384 | 0.1980 |
| Baseline (ALS)* | 0.5780 | 1.1119 | 1.2020 | 0.2974 | 0.1788 |
| SVD-ALS1 | 79.5536 | 0.5627 | 1.1960 | 0.8200 | 0.1870 |
| SVD-ALS2 | 82.5507 | 0.5651 | 1.2010 | 0.8185 | 0.1801 |
| SVD-SGD* | 7.5524 | 0.8267 | 1.2046 | 0.6116 | 0.1752 |
| SVD++-SGD* | 43.6945 | 0.8738 | 1.2025 | 0.5661 | 0.1780 |
| NMF-SGD* | 9.3785 | 0.3666 | 1.3761 | 0.9236 | -0.0765 |
| Slope one* | 1.8091 | 0.3685 | 1.3870 | 0.9228 | -0.0935 |
| Co-clustering* | 7.8524 | 0.7938 | 1.3291 | 0.6419 | -0.0041 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ridge regression | 0.5500 | 1.0158 | 1.0062 | 0.4135 | 0.4245 |
| Random forest | 10.1126 | 0.9938 | 0.9896 | 0.4388 | 0.4434 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ensemble1 (weighted average) | 0.0000 | 0.8050 | 1.1919 | 0.6317 | 0.1925 |
| Ensemble1 (Ridge regression) | 0.0150 | 0.9371 | 1.1872 | 0.5010 | 0.1988 |
| Ensemble1 (random forest) | 1.2871 | 0.9703 | 1.1882 | 0.4650 | 0.1974 |
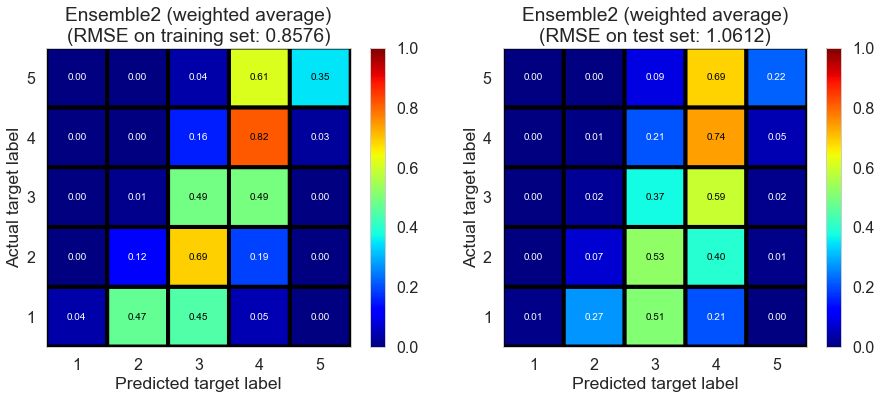
| Ensemble2 (weighted average) | 0.0000 | 0.8576 | 1.0612 | 0.5820 | 0.3598 |
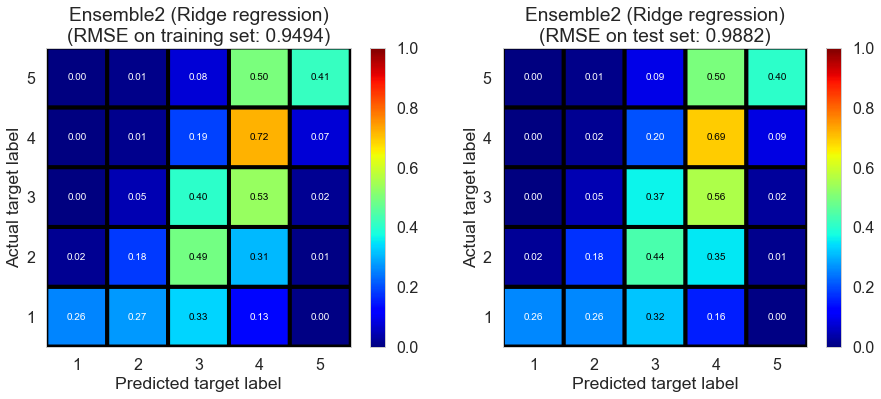
| Ensemble2 (Ridge regression) | 0.0170 | 0.9494 | 0.9882 | 0.4878 | 0.4449 |
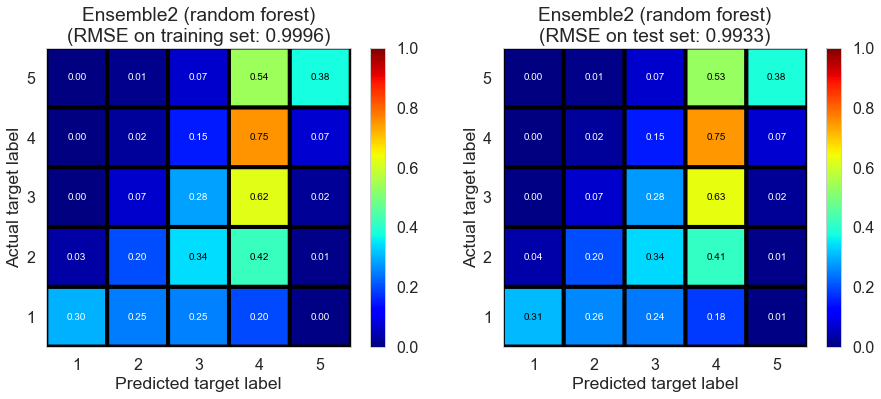
| Ensemble2 (random forest) | 1.7071 | 0.9996 | 0.9933 | 0.4322 | 0.4391 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)
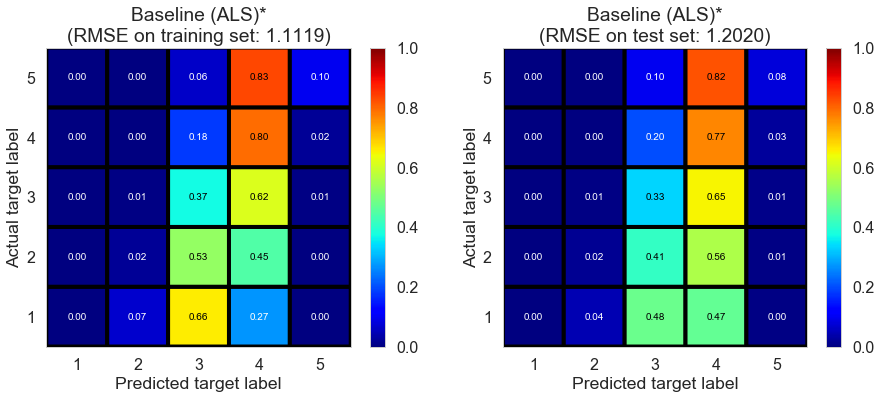
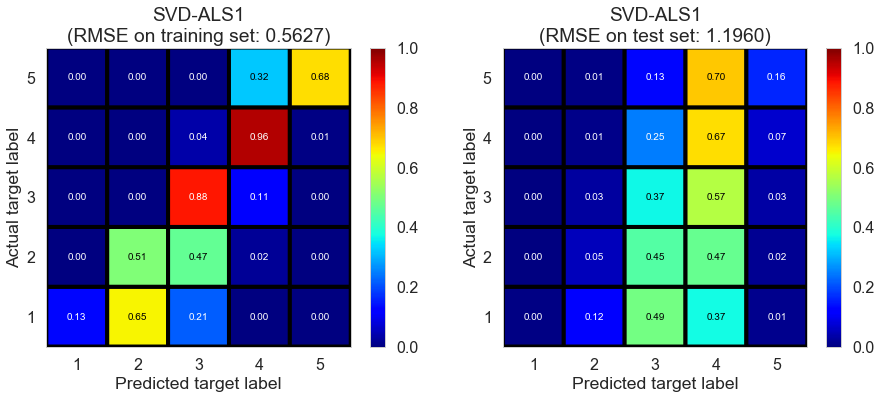
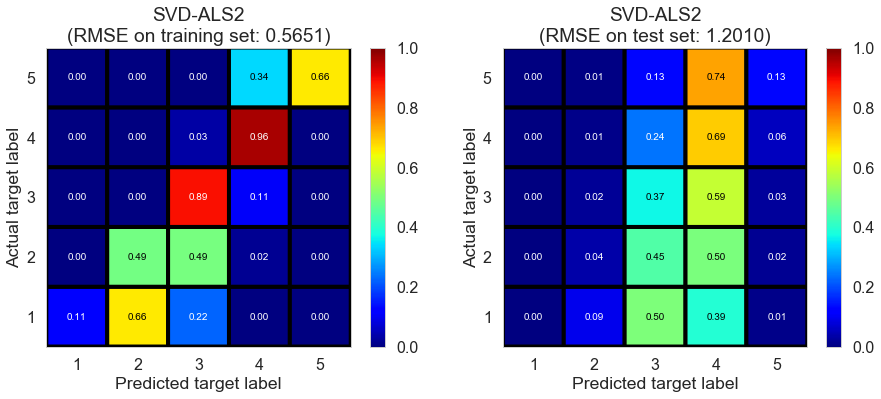
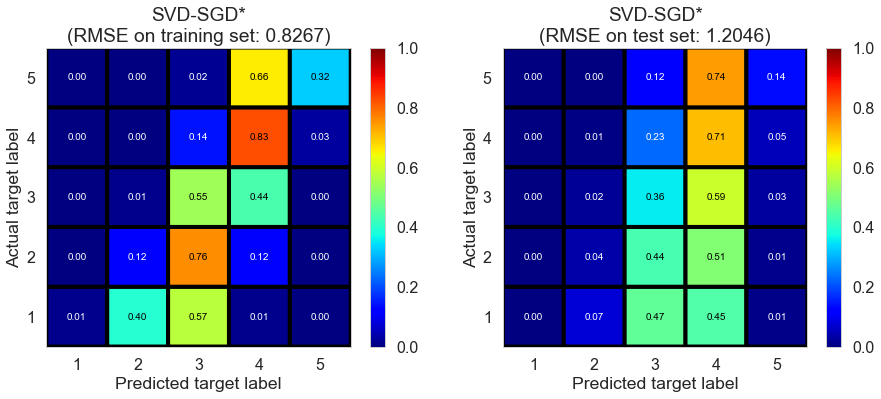
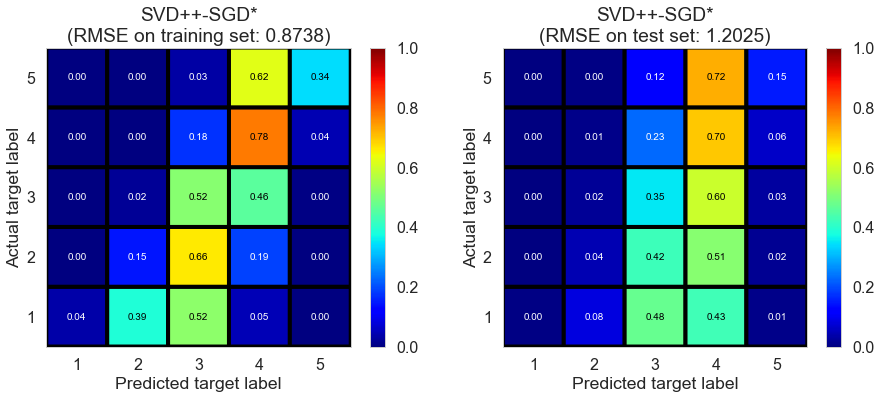
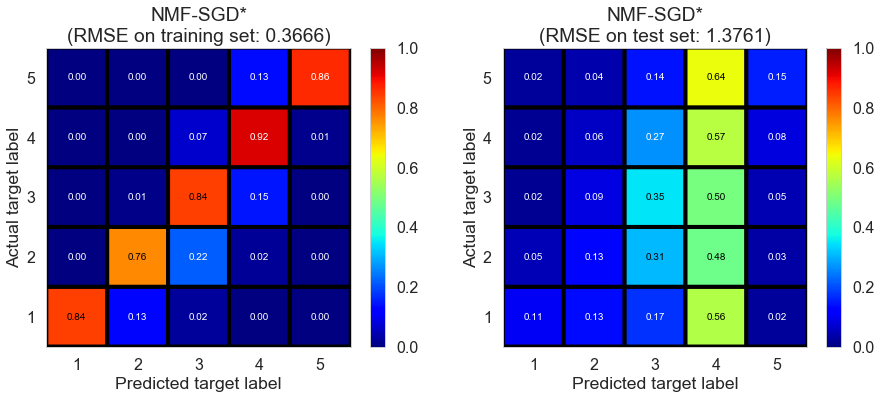
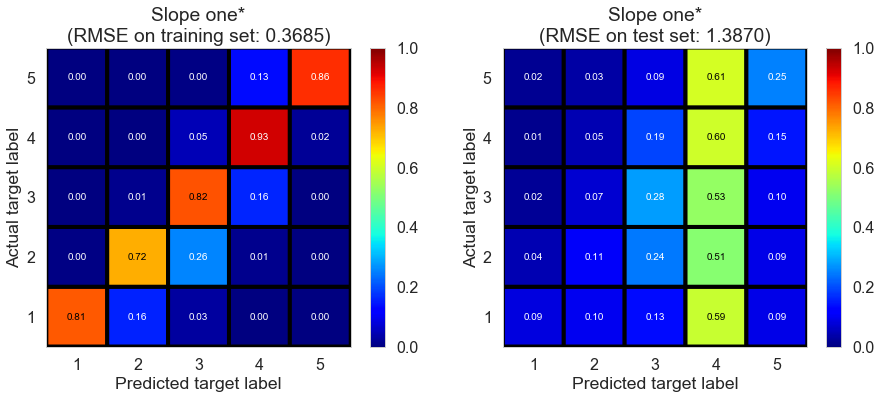
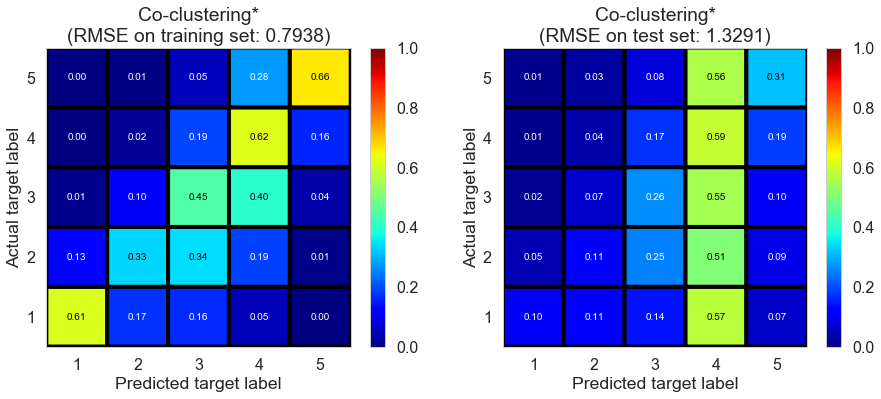
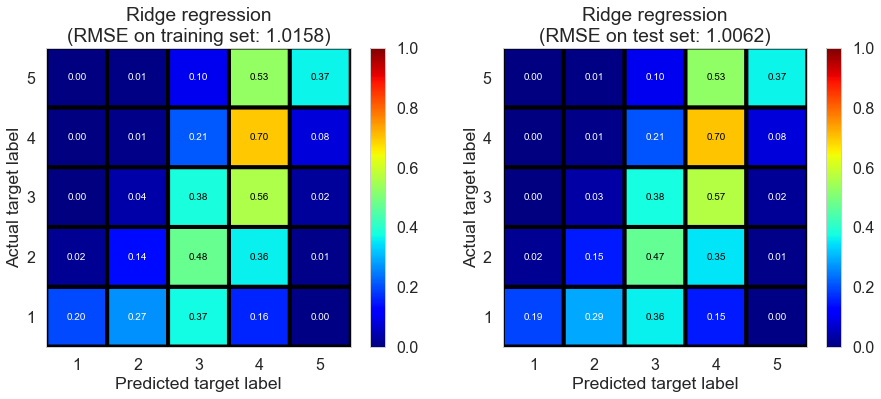
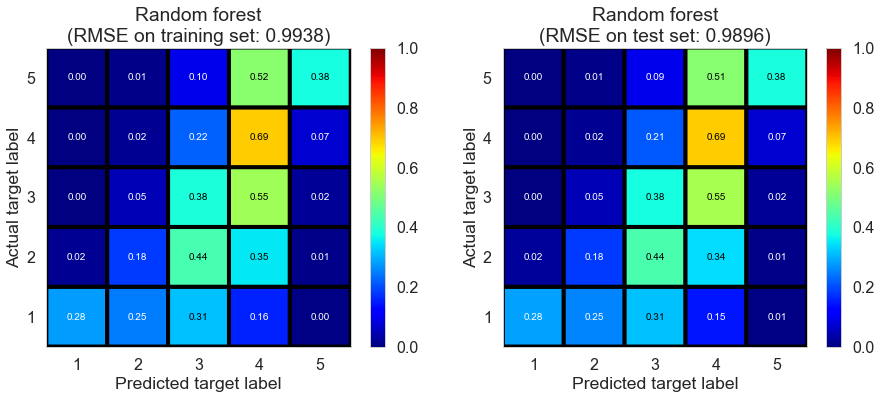
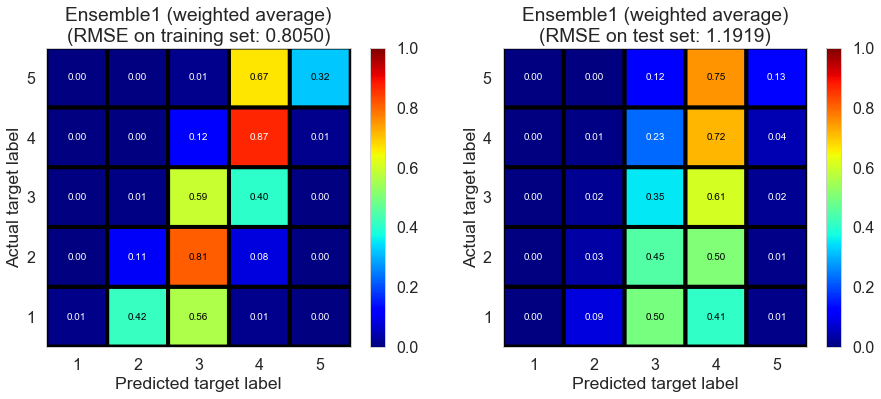
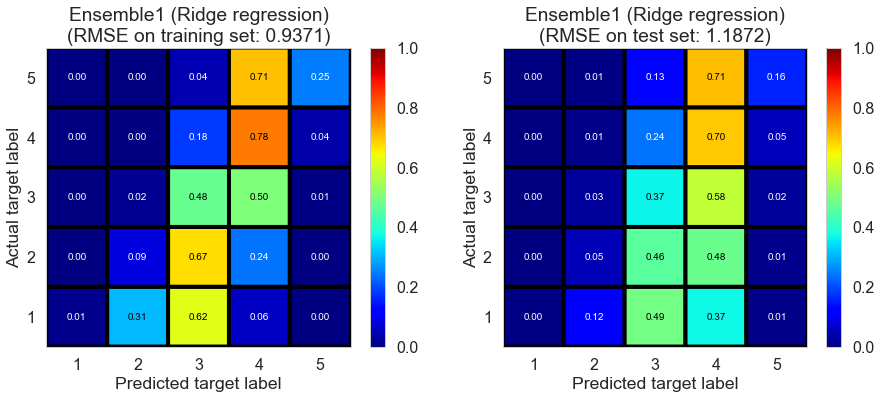

Toronto (331407 reviews, 12118 restaurants, 77506 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Mode estimator | 0.0000 | 1.8830 | 1.8801 | -1.1173 | -1.1219 |
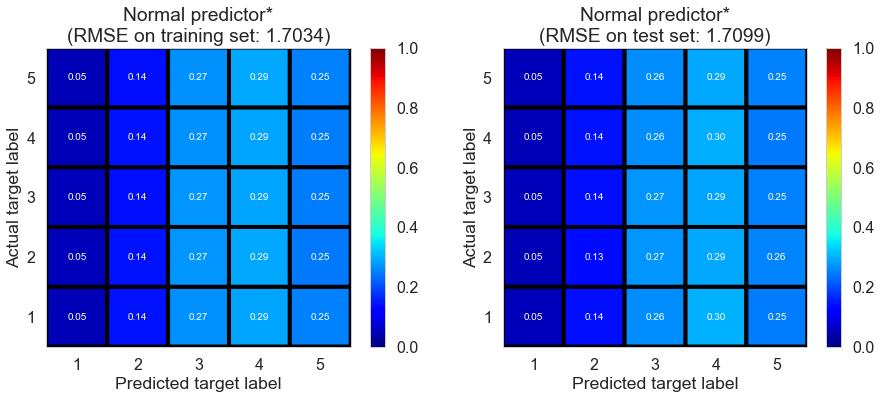
| Normal predictor* | 1.0181 | 1.7034 | 1.7099 | -0.7326 | -0.7552 |
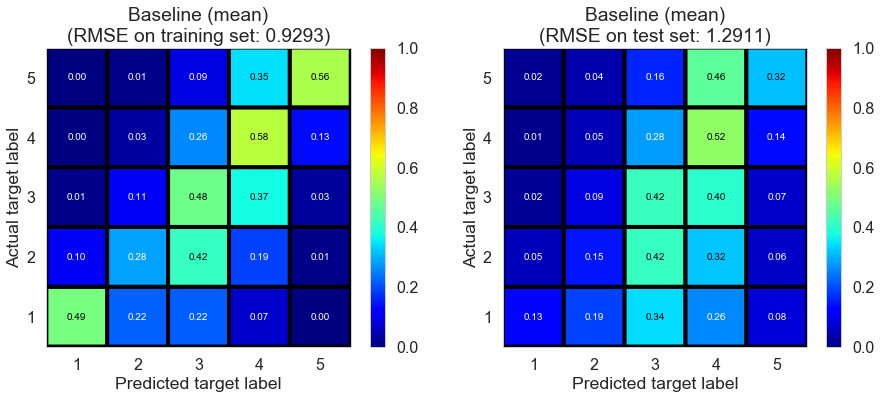
| Baseline (mean) | 0.2360 | 0.9293 | 1.2911 | 0.4843 | -0.0006 |
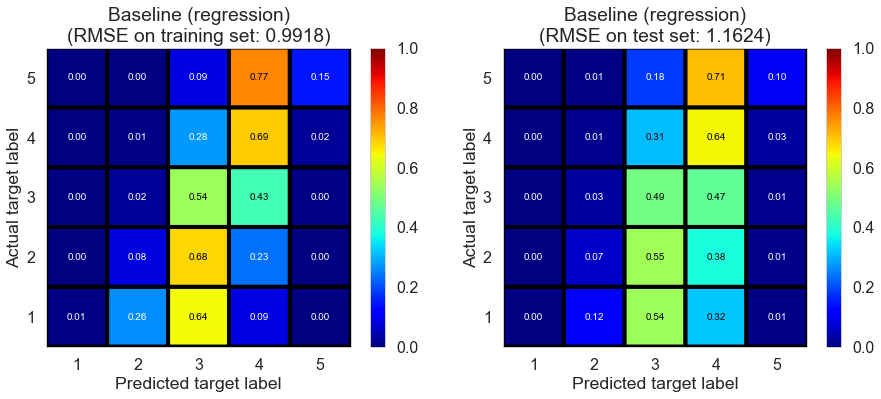
| Baseline (regression) | 0.6270 | 0.9918 | 1.1624 | 0.4126 | 0.1890 |
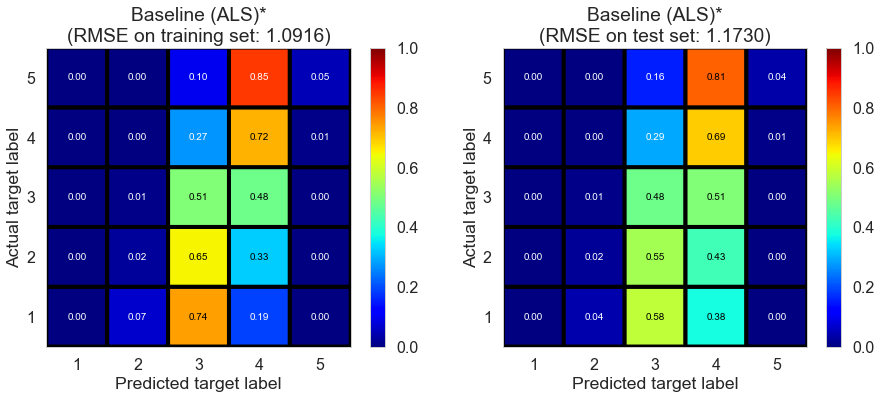
| Baseline (ALS)* | 1.6651 | 1.0916 | 1.1730 | 0.2884 | 0.1740 |
| SVD-ALS1 | 168.3716 | 0.5614 | 1.1751 | 0.8118 | 0.1711 |
| SVD-ALS2 | 169.0347 | 0.5634 | 1.1795 | 0.8104 | 0.1649 |
| SVD-SGD* | 17.6360 | 0.8222 | 1.1772 | 0.5963 | 0.1681 |
| SVD++-SGD* | 119.8469 | 0.8730 | 1.1763 | 0.5449 | 0.1694 |
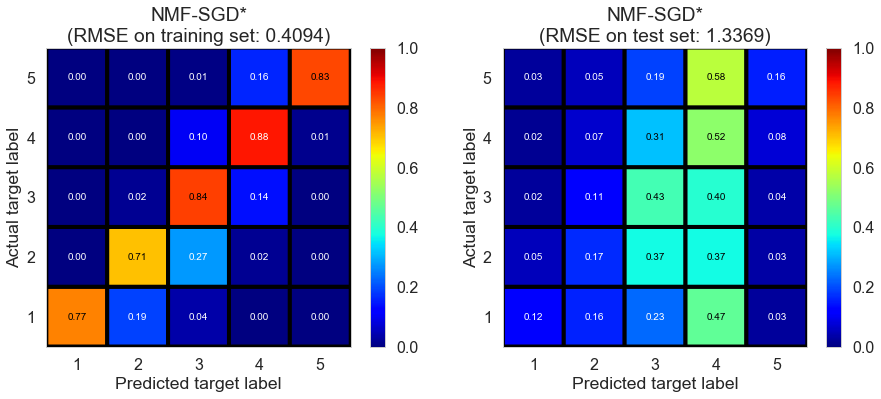
| NMF-SGD* | 22.2953 | 0.4094 | 1.3369 | 0.8999 | -0.0729 |
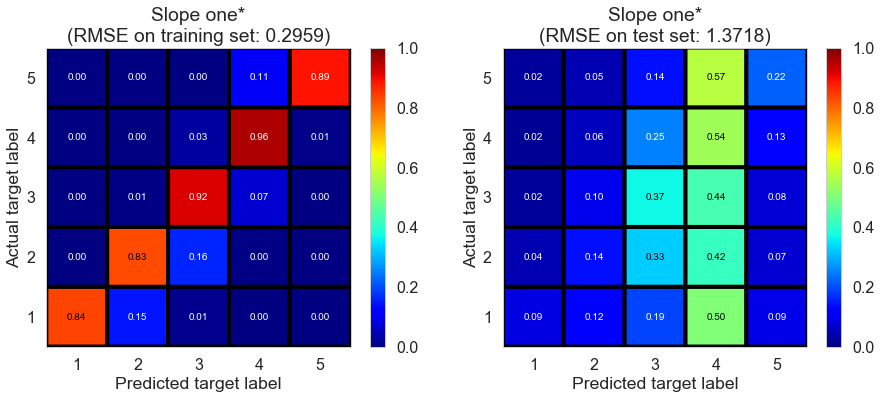
| Slope one* | 7.2904 | 0.2959 | 1.3718 | 0.9477 | -0.1296 |
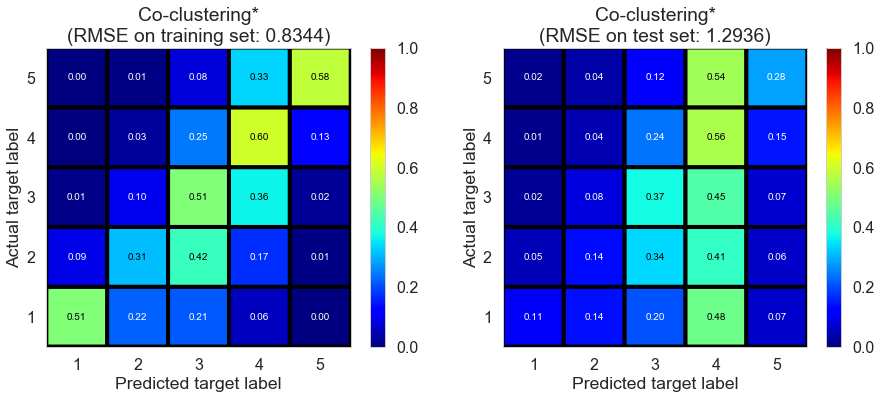
| Co-clustering* | 17.0870 | 0.8344 | 1.2936 | 0.5842 | -0.0045 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
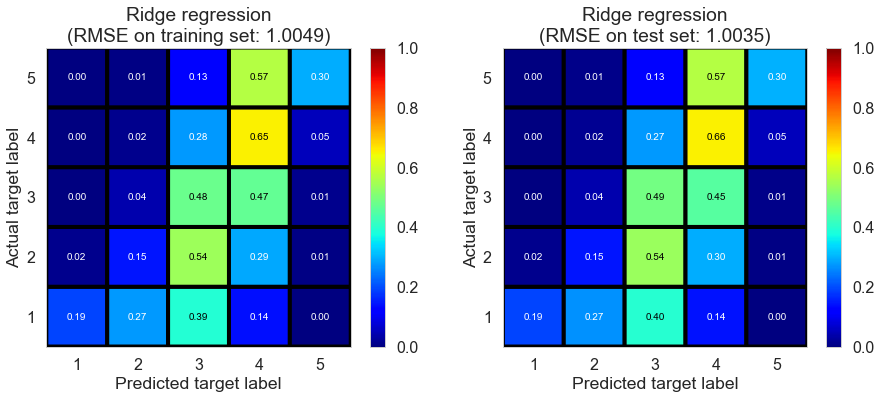
| Ridge regression | 1.1401 | 1.0049 | 1.0035 | 0.3970 | 0.3955 |
| Random forest | 27.0035 | 0.9891 | 0.9909 | 0.4158 | 0.4106 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ensemble1 (weighted average) | 0.0000 | 0.8044 | 1.1661 | 0.6136 | 0.1837 |
| Ensemble1 (Ridge regression) | 0.0290 | 1.0152 | 1.1620 | 0.3845 | 0.1895 |
| Ensemble1 (random forest) | 3.2312 | 0.9977 | 1.1637 | 0.4056 | 0.1872 |
| Ensemble2 (weighted average) | 0.0000 | 0.8564 | 1.0542 | 0.5620 | 0.3329 |
| Ensemble2 (Ridge regression) | 0.0390 | 1.0111 | 0.9879 | 0.3895 | 0.4141 |
| Ensemble2 (random forest) | 4.1512 | 0.9948 | 0.9962 | 0.4090 | 0.4043 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)
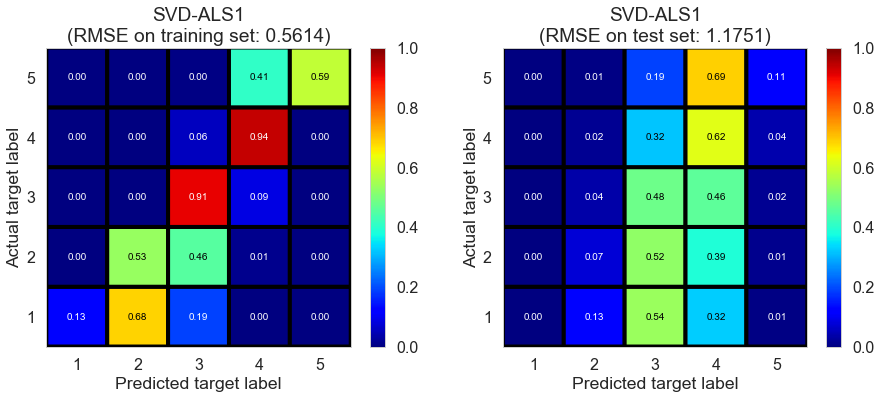
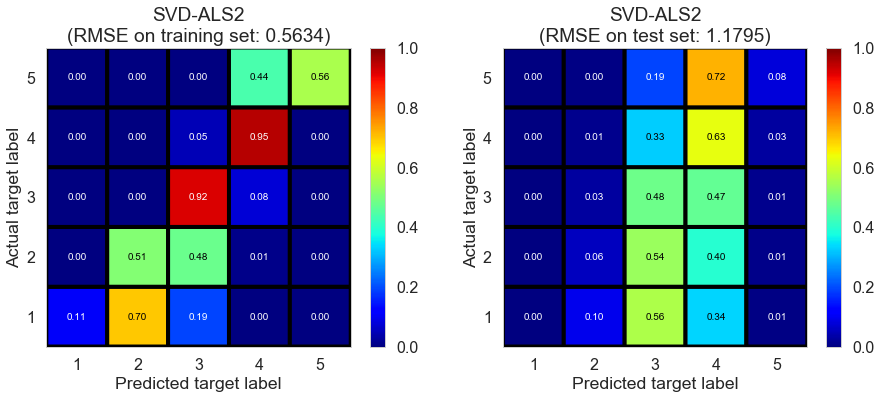
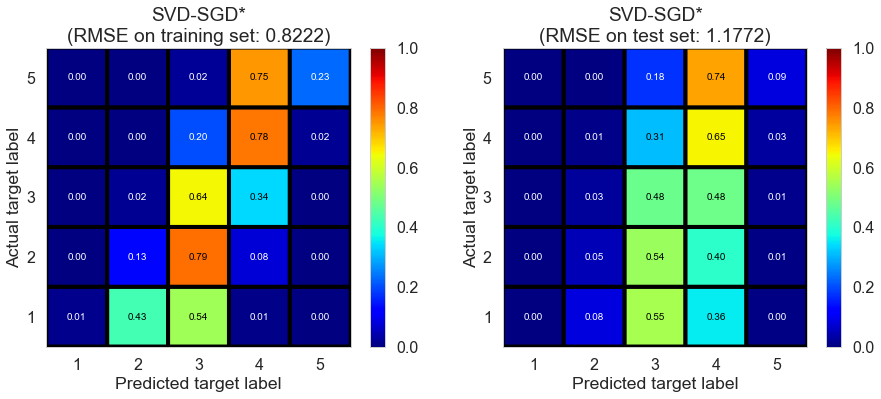
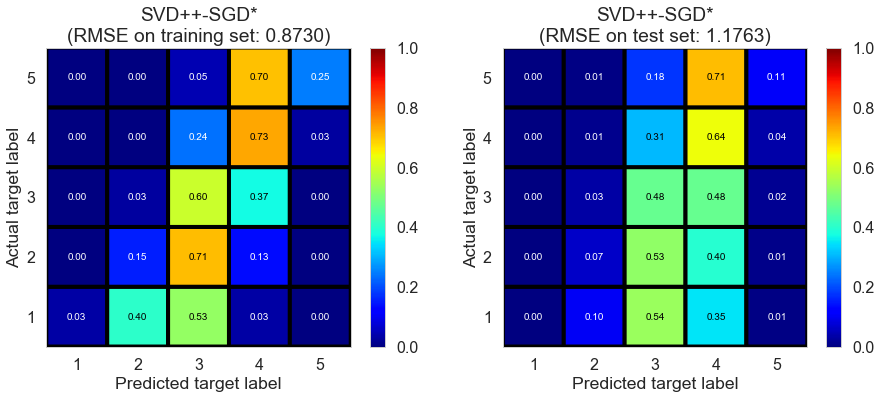
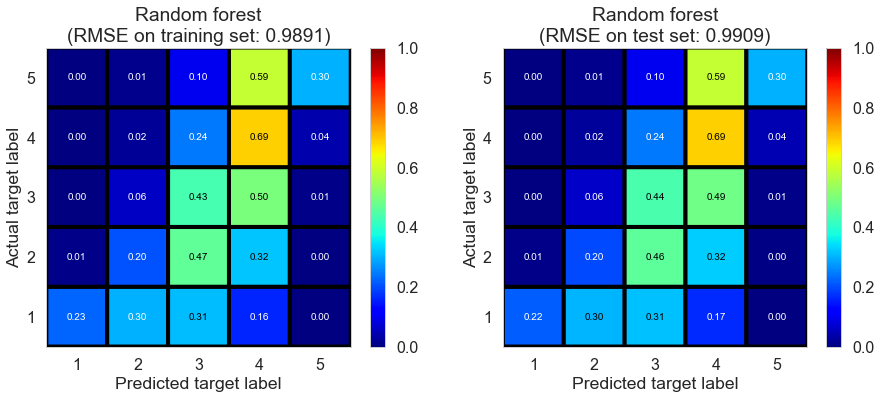
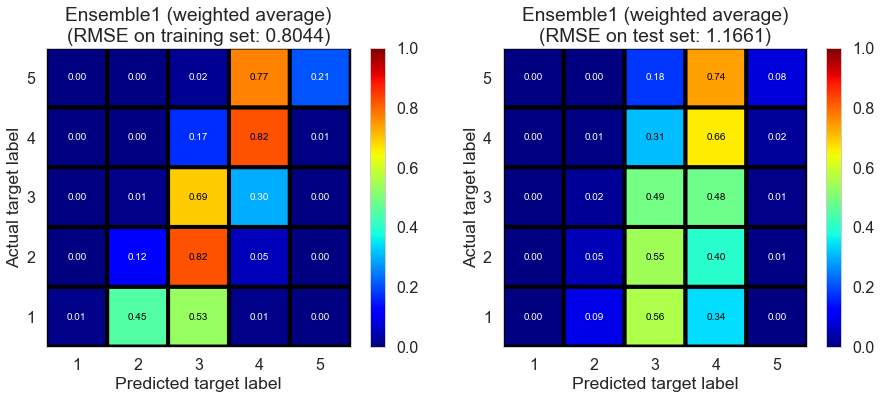
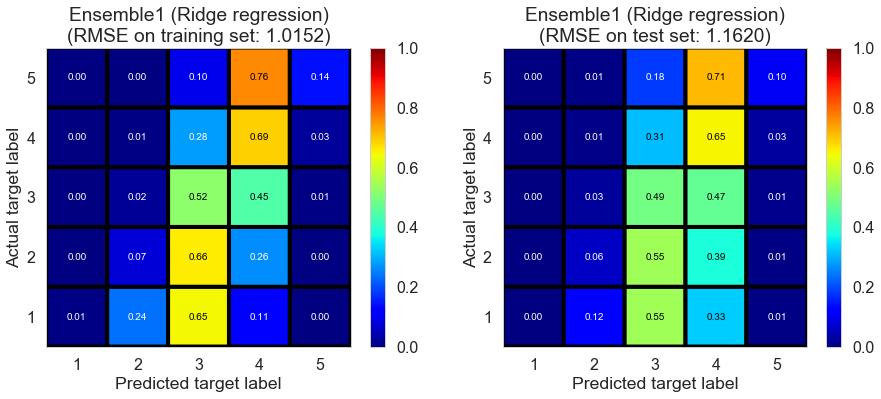
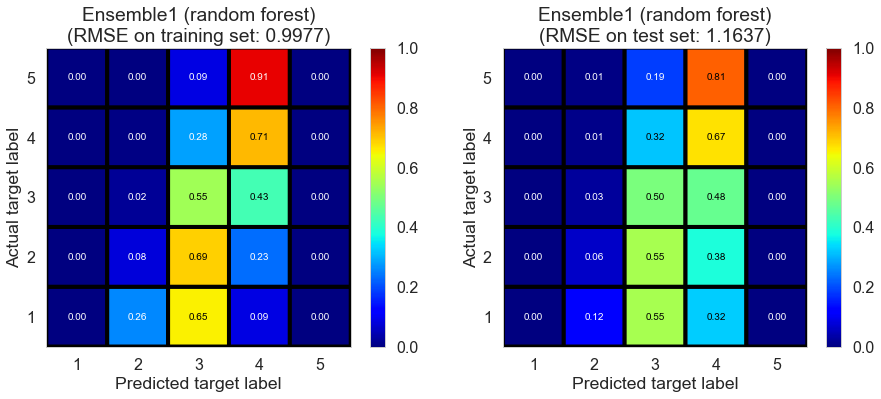
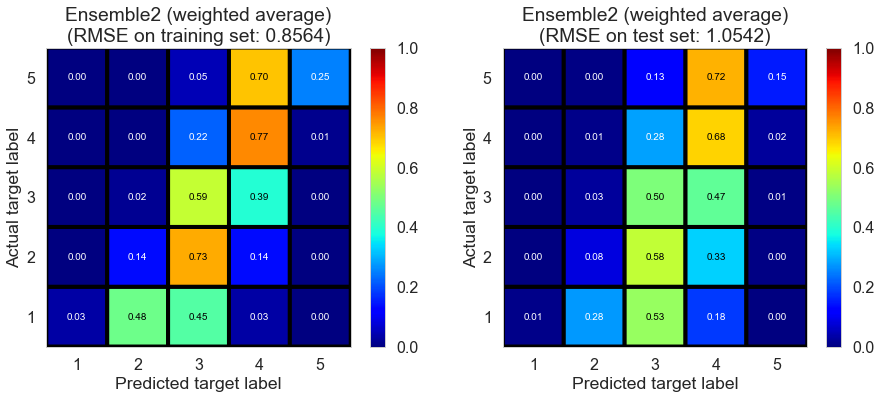
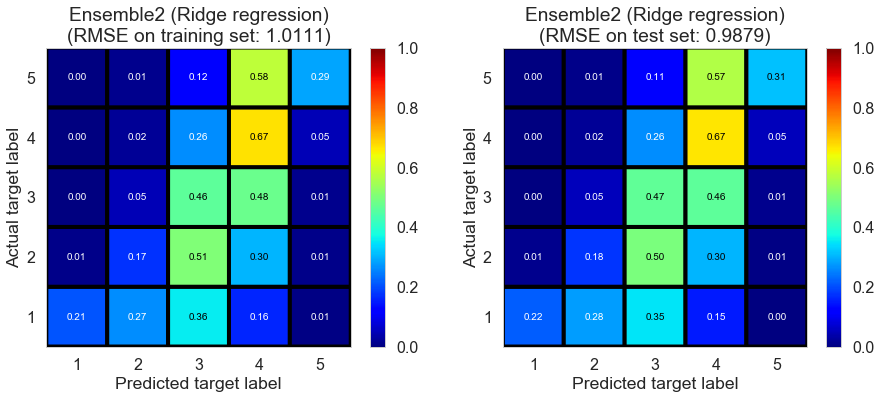
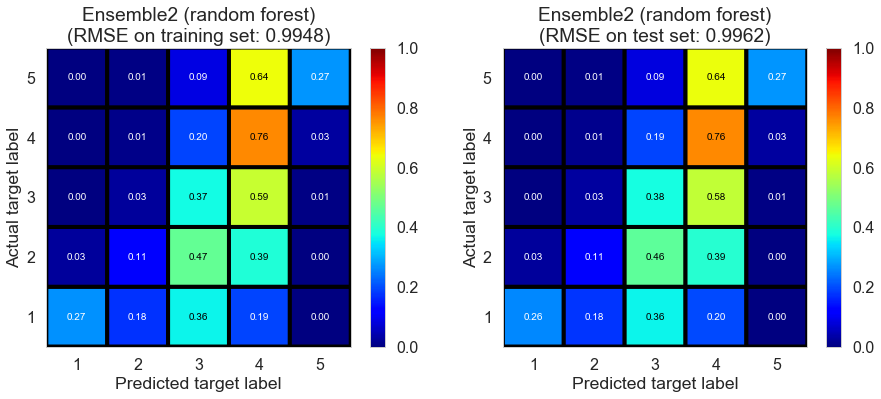
Las_Vegas (1280896 reviews, 20434 restaurants, 429363 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Mode estimator | 0.0000 | 1.9060 | 1.9073 | -0.7549 | -0.7578 |
| Normal predictor* | 5.3933 | 1.8565 | 1.8573 | -0.6649 | -0.6667 |
| Baseline (mean) | 1.1371 | 0.9990 | 1.4148 | 0.5179 | 0.0329 |
| Baseline (regression) | 5.9963 | 1.0732 | 1.2612 | 0.4436 | 0.2314 |
| Baseline (ALS)* | 6.9174 | 1.1880 | 1.2696 | 0.3182 | 0.2211 |
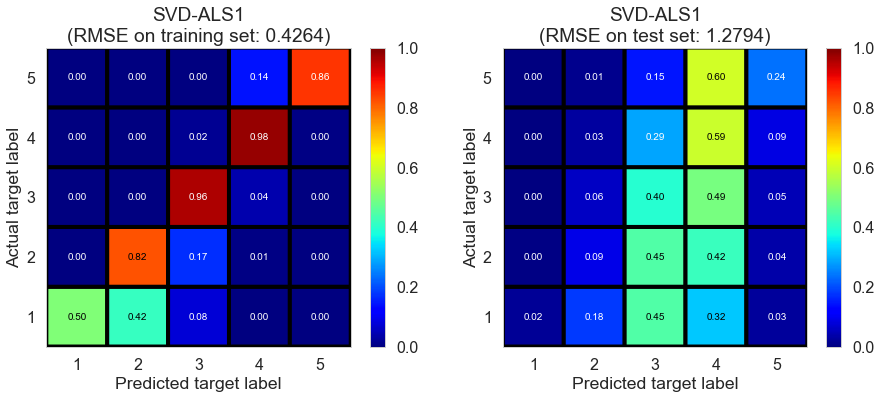
| SVD-ALS1 | 652.1173 | 0.4264 | 1.2794 | 0.9122 | 0.2091 |
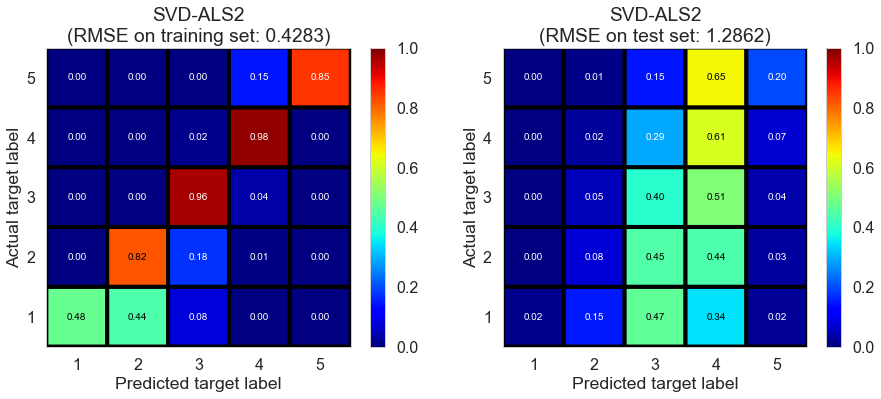
| SVD-ALS2 | 674.9286 | 0.4283 | 1.2862 | 0.9114 | 0.2007 |
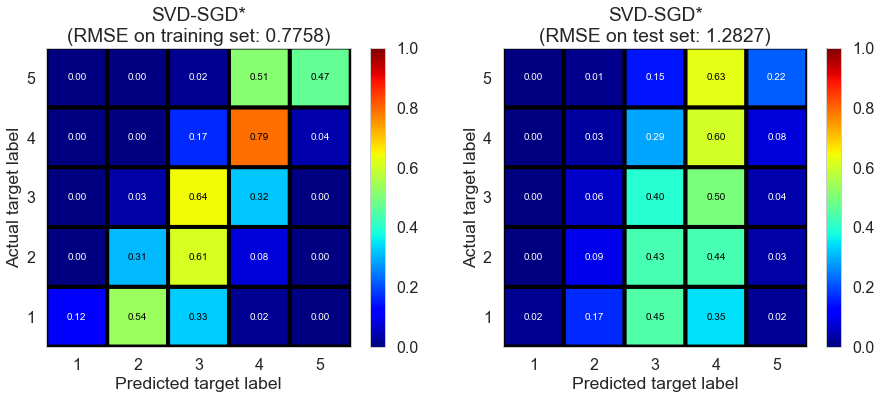
| SVD-SGD* | 70.6220 | 0.7758 | 1.2827 | 0.7093 | 0.2050 |
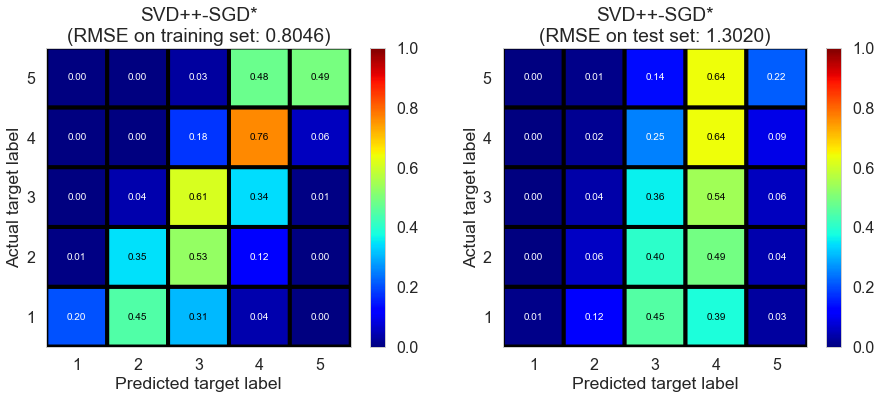
| SVD++-SGD* | 333.8711 | 0.8046 | 1.3020 | 0.6873 | 0.1809 |
| NMF-SGD* | 92.4893 | 0.4178 | 1.4916 | 0.9157 | -0.0750 |
| Slope one* | 24.1324 | 0.4314 | 1.5076 | 0.9101 | -0.0983 |
| Co-clustering* | 77.2254 | 0.8555 | 1.4343 | 0.6464 | 0.0060 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ridge regression | 5.0093 | 1.1216 | 1.1226 | 0.3923 | 0.3911 |
| Random forest | 154.2278 | 1.1008 | 1.1029 | 0.4146 | 0.4122 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ensemble1 (weighted average) | 0.0000 | 0.7633 | 1.2648 | 0.7185 | 0.2270 |
| Ensemble1 (Ridge regression) | 0.1270 | 1.0514 | 1.2600 | 0.4660 | 0.2329 |
| Ensemble1 (random forest) | 13.2948 | 1.0838 | 1.2617 | 0.4326 | 0.2308 |
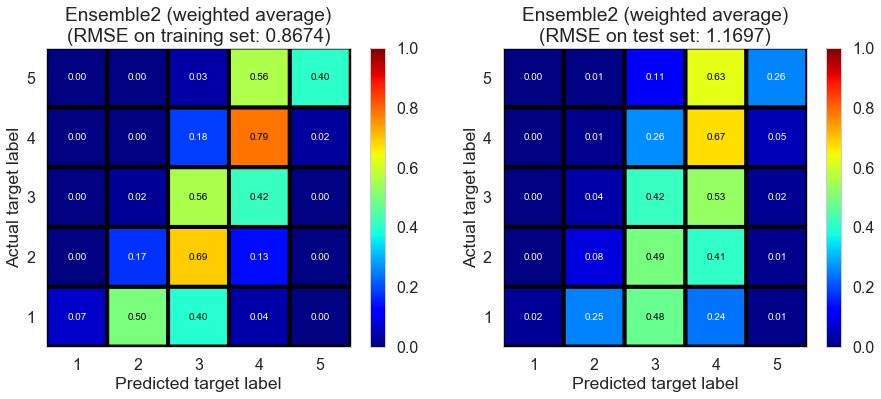
| Ensemble2 (weighted average) | 0.0000 | 0.8674 | 1.1697 | 0.6366 | 0.3389 |
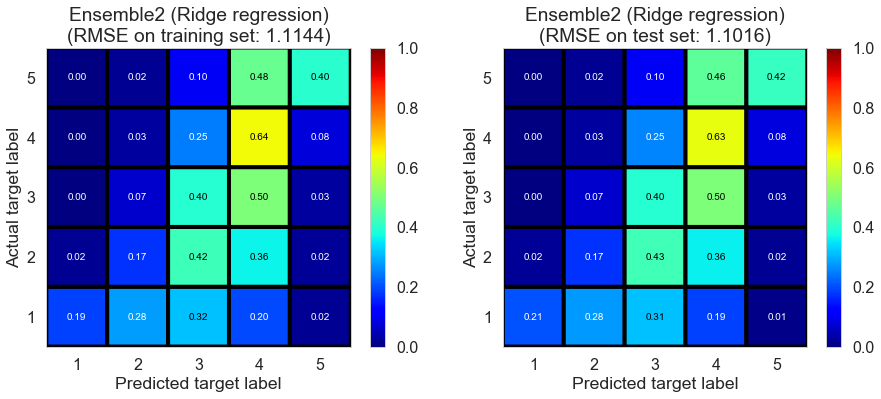
| Ensemble2 (Ridge regression) | 0.1520 | 1.1144 | 1.1016 | 0.4001 | 0.4136 |
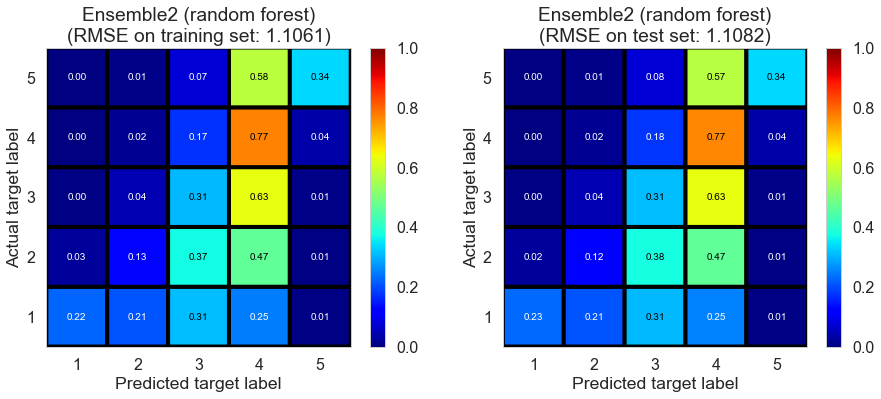
| Ensemble2 (random forest) | 16.9300 | 1.1061 | 1.1082 | 0.4090 | 0.4066 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)
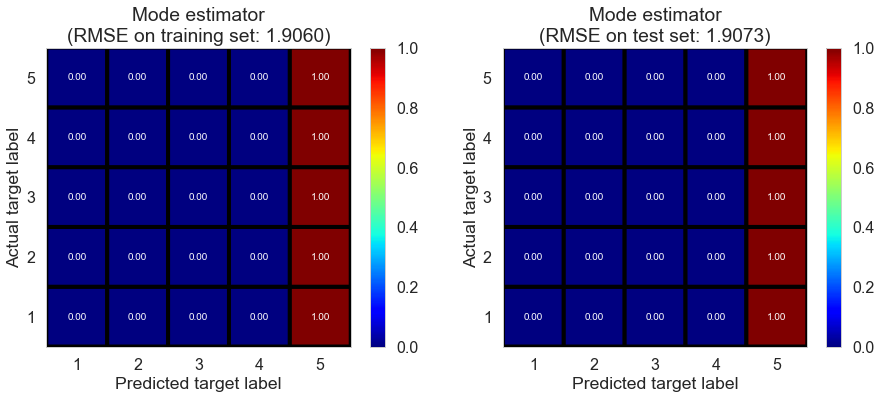
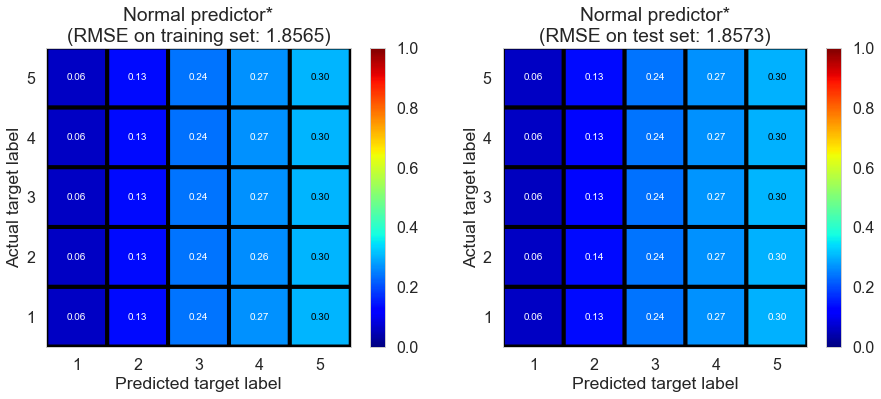
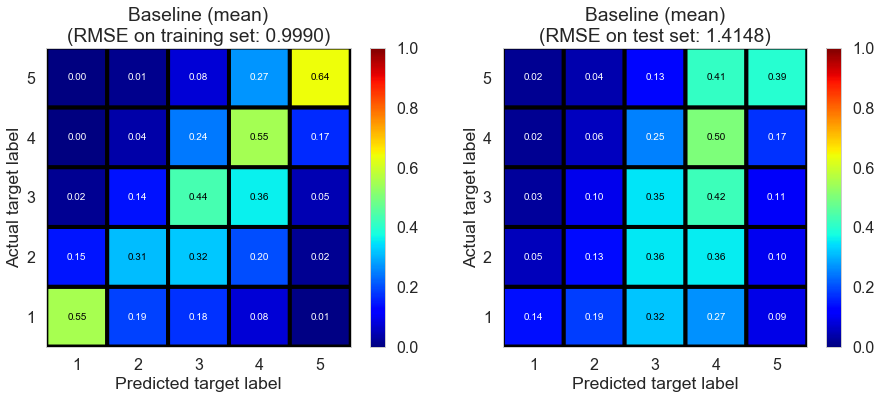
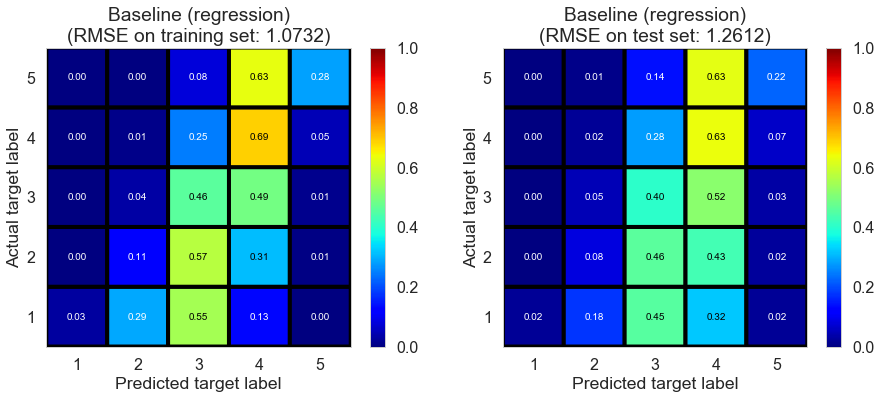
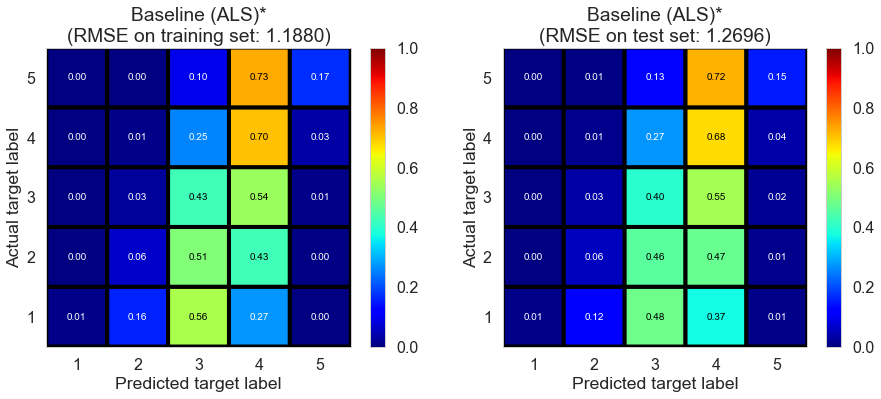
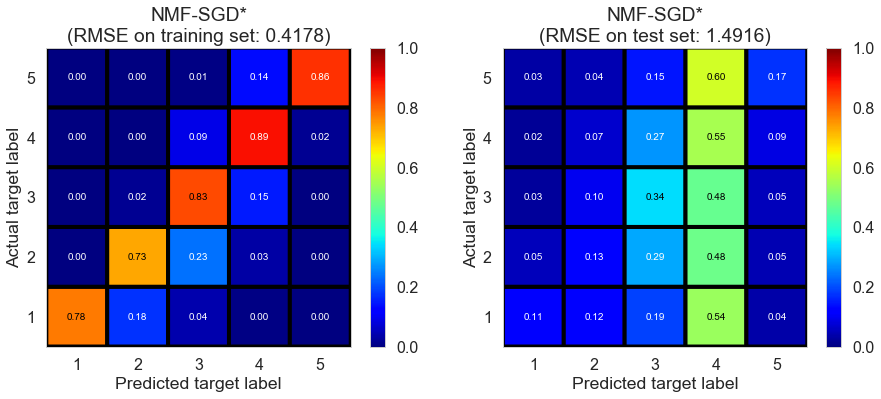
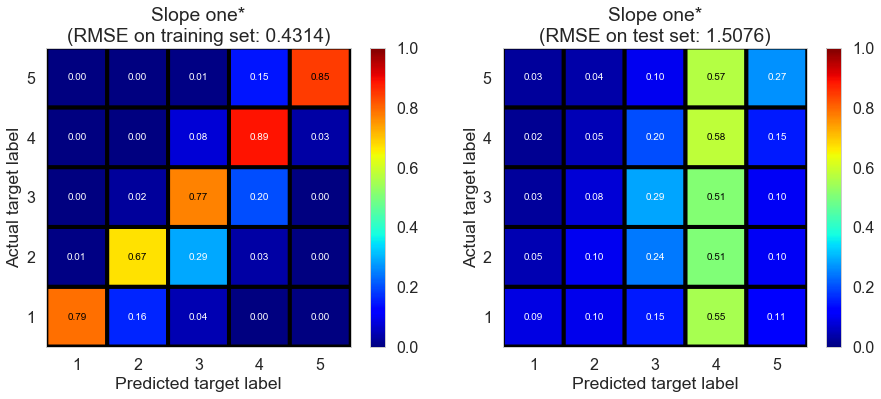
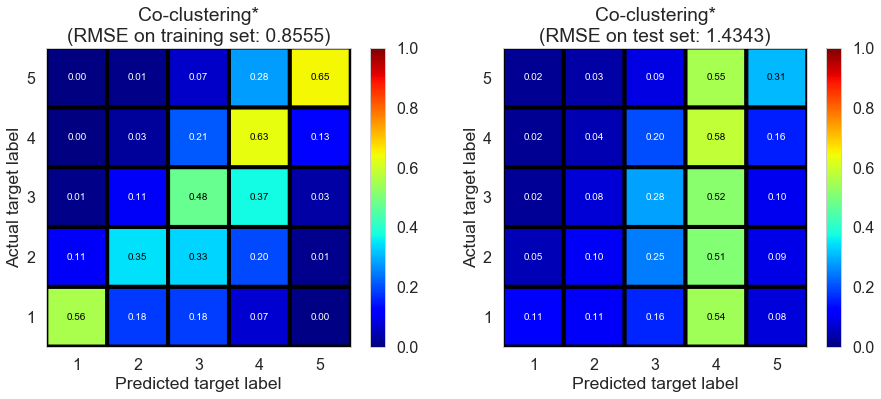
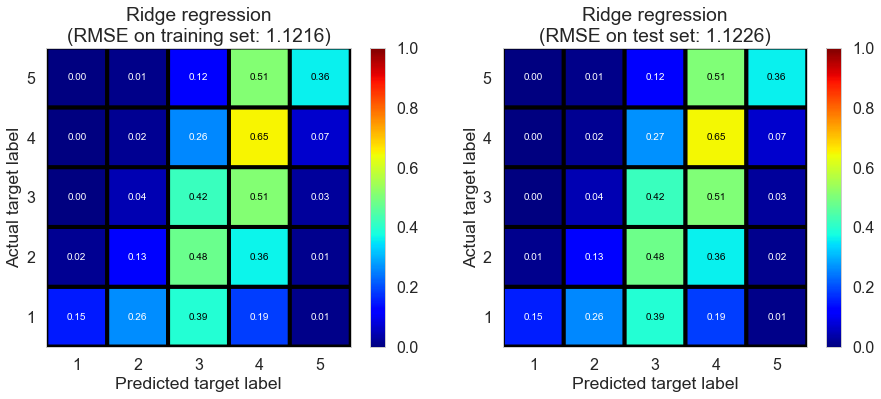
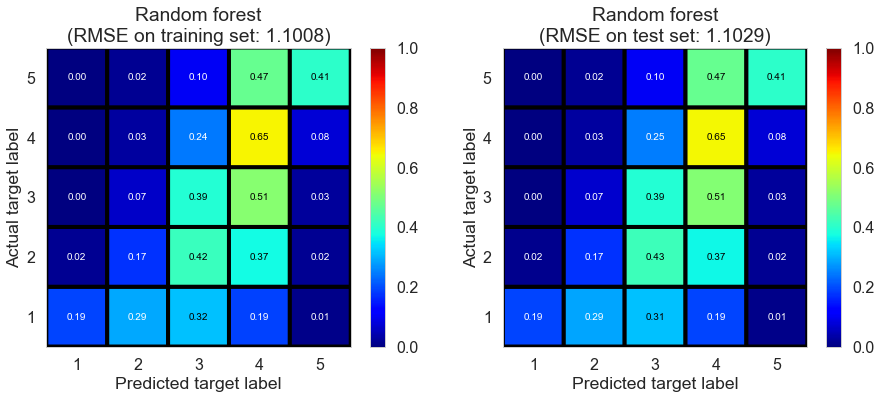
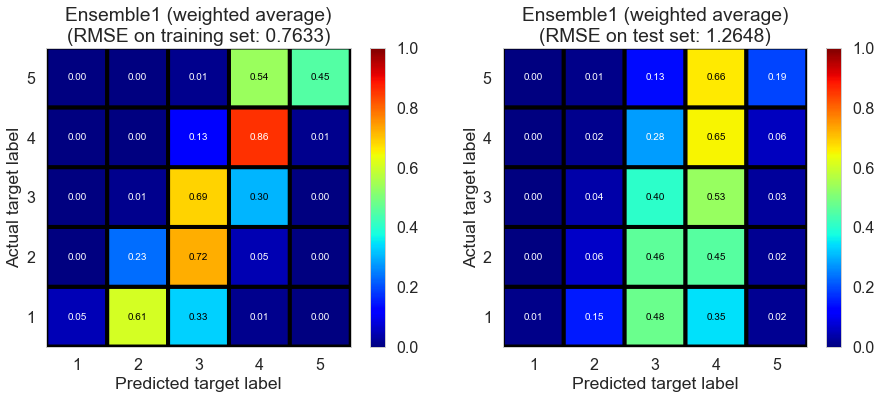
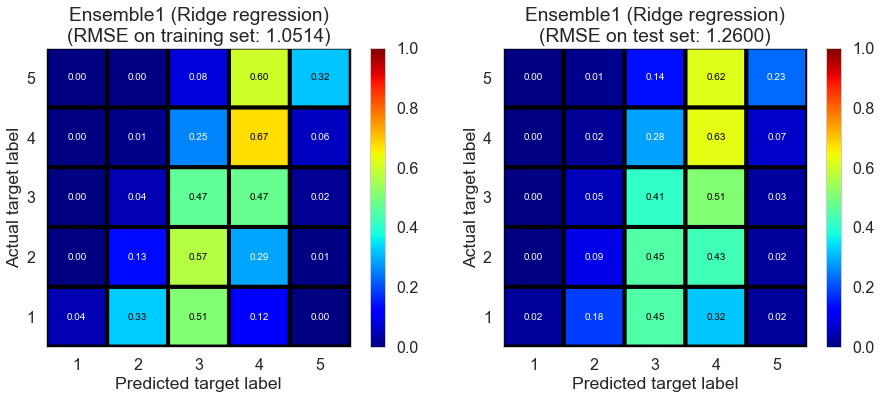
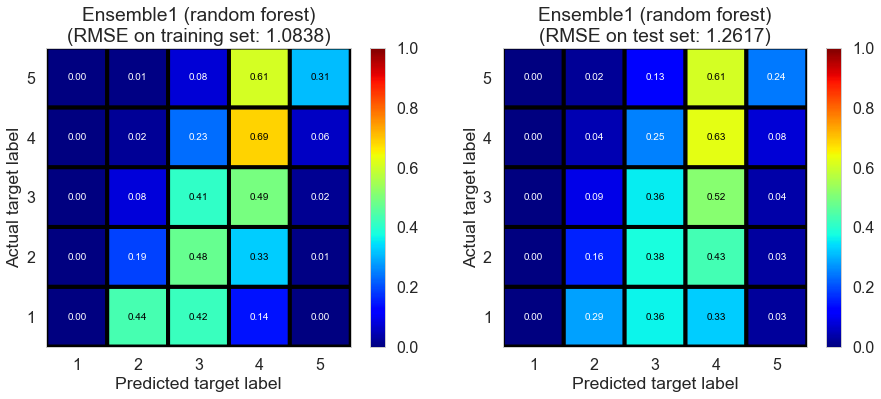
Full (4166778 reviews, 131025 restaurants, 1117891 users)
| Collaborative filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
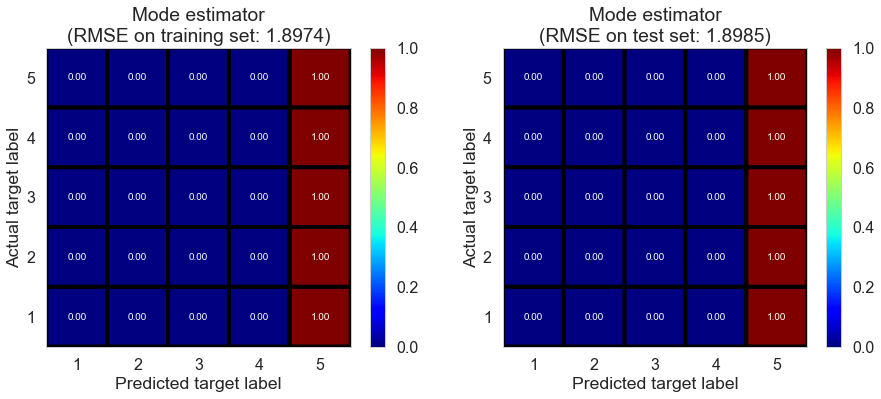
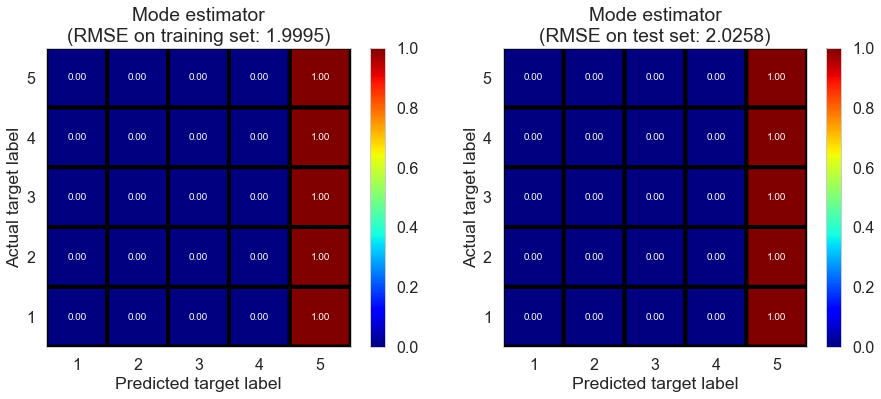
| Mode estimator | 0.0000 | 1.8974 | 1.8985 | -0.7803 | -0.7799 |
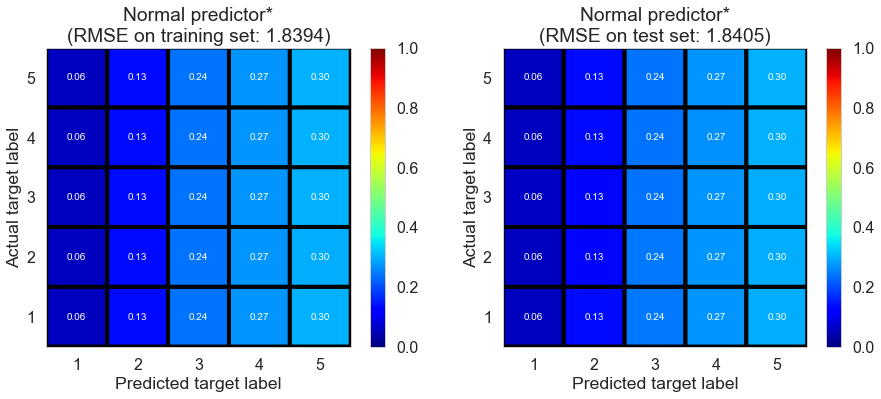
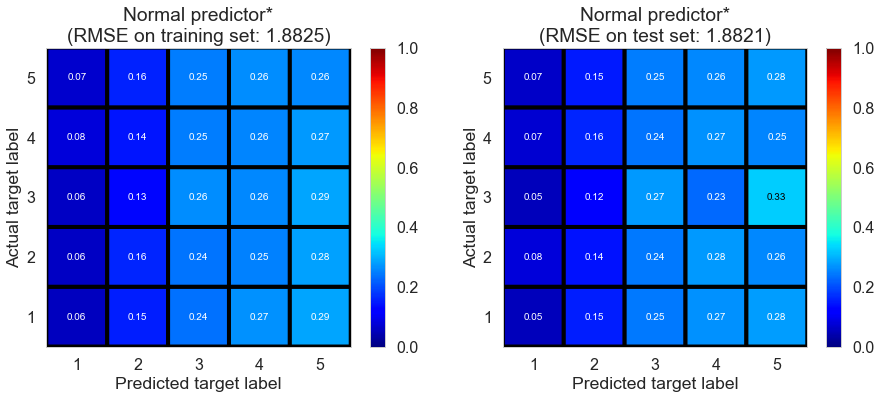
| Normal predictor* | 19.3631 | 1.8394 | 1.8405 | -0.6729 | -0.6727 |
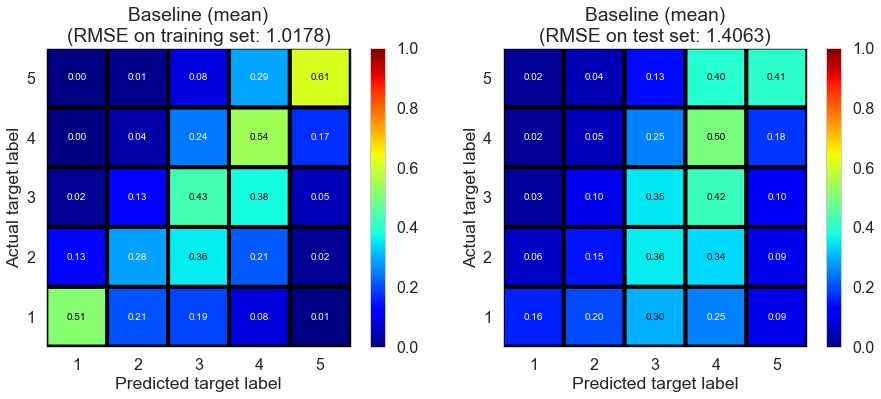
| Baseline (mean) | 4.6053 | 1.0178 | 1.4063 | 0.4878 | 0.0234 |
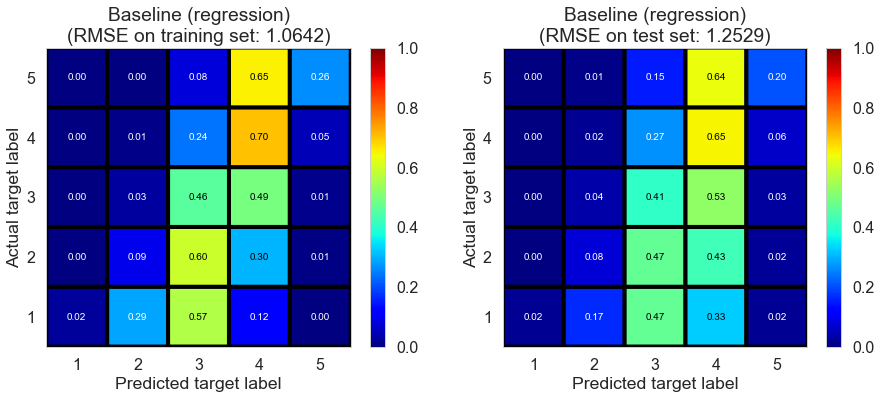
| Baseline (regression) | 21.4822 | 1.0642 | 1.2529 | 0.4400 | 0.2248 |
| Baseline (ALS)* | 27.2096 | 1.1754 | 1.2659 | 0.3169 | 0.2086 |
| SVD-ALS1 | 2153.7902 | 0.5313 | 1.2691 | 0.8604 | 0.2046 |
| SVD-ALS2 | 2268.9128 | 0.5332 | 1.2756 | 0.8594 | 0.1965 |
| SVD-SGD* | 242.1499 | 0.8312 | 1.2721 | 0.6584 | 0.2008 |
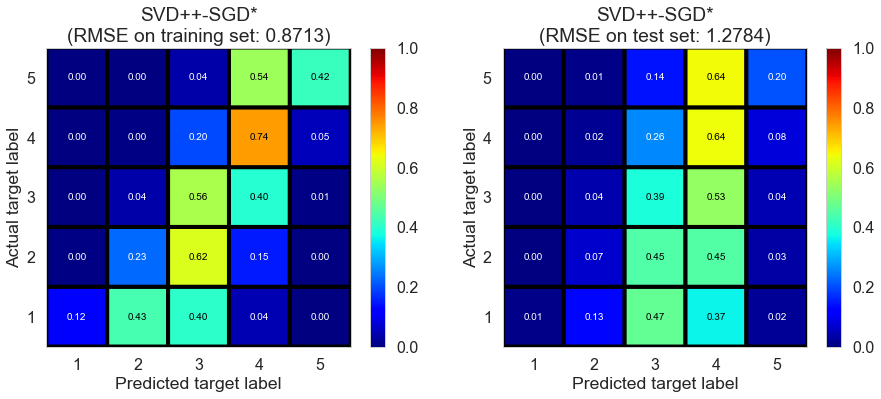
| SVD++-SGD* | 1473.2923 | 0.8713 | 1.2784 | 0.6246 | 0.1930 |
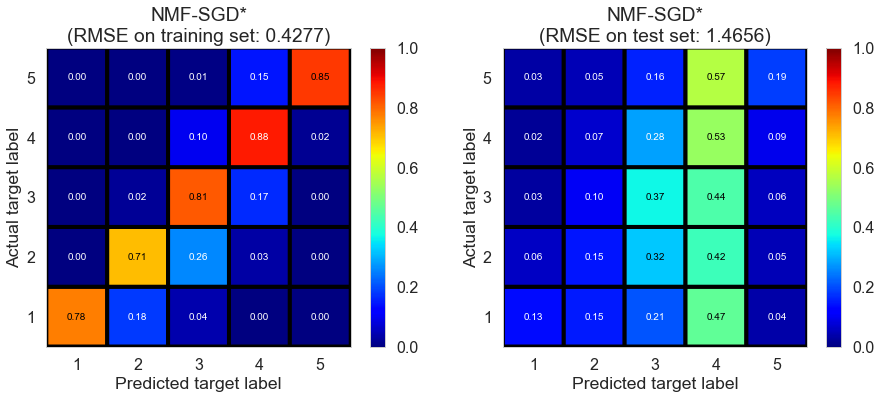
| NMF-SGD* | 323.9235 | 0.4277 | 1.4656 | 0.9095 | -0.0607 |
(* shows the algorithms we implemented by wrapping around methods in scikit-surprise python package)
| Content filtering | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
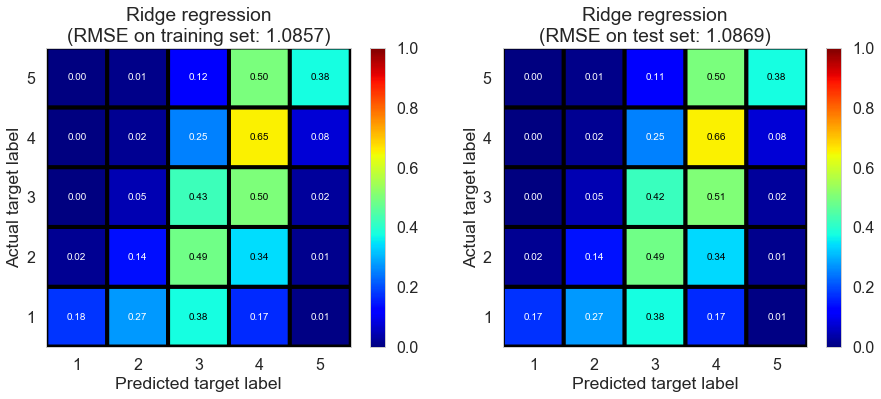
| Ridge regression | 17.1610 | 1.0857 | 1.0869 | 0.4171 | 0.4167 |
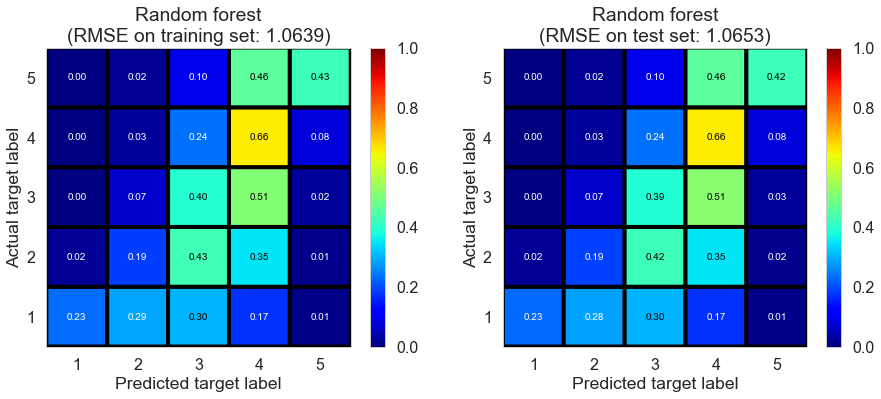
| Random forest | 663.2849 | 1.0639 | 1.0653 | 0.4403 | 0.4396 |
| Ensemble estimators | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
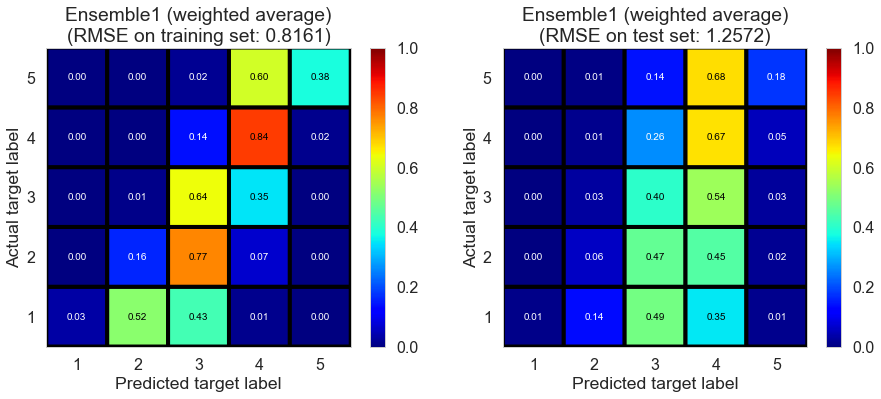
| Ensemble1 (weighted average) | 0.0000 | 0.8161 | 1.2572 | 0.6706 | 0.2195 |
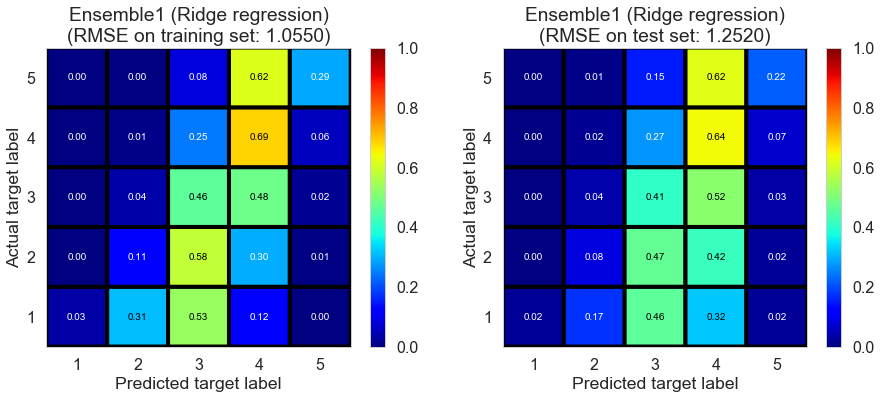
| Ensemble1 (Ridge regression) | 0.4160 | 1.0550 | 1.2520 | 0.4496 | 0.2260 |
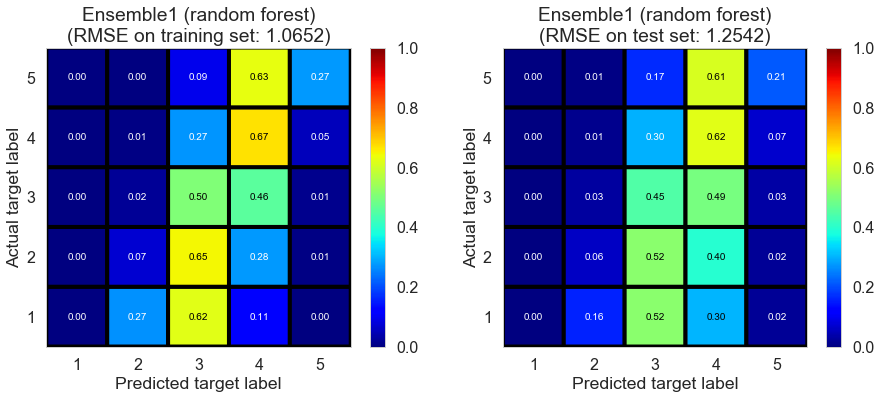
| Ensemble1 (random forest) | 56.0282 | 1.0652 | 1.2542 | 0.4389 | 0.2233 |
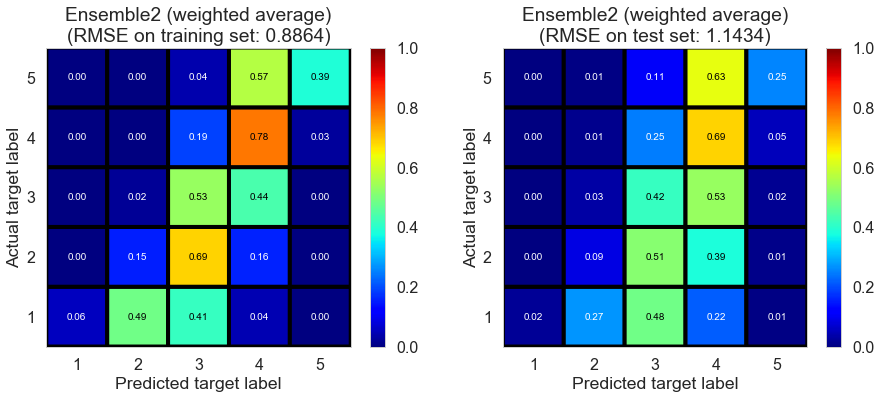
| Ensemble2 (weighted average) | 0.0000 | 0.8864 | 1.1434 | 0.6115 | 0.3545 |
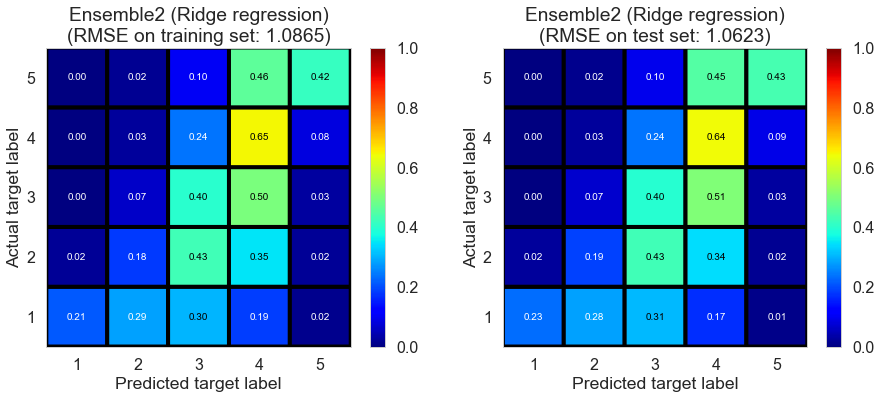
| Ensemble2 (Ridge regression) | 0.5530 | 1.0865 | 1.0623 | 0.4163 | 0.4427 |
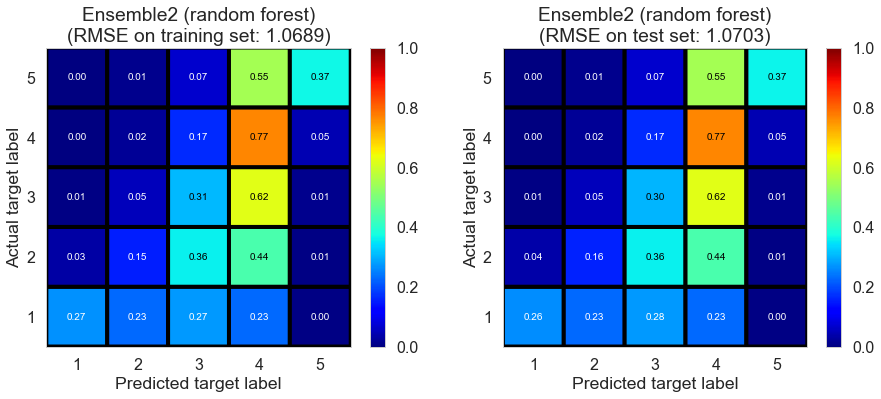
| Ensemble2 (random forest) | 69.6950 | 1.0689 | 1.0703 | 0.4351 | 0.4343 |
(Ensemble1 represents the ensemble of collaborative filtering models; Ensemble2 represents the ensemble of collaborative filtering and content filtering models)