Content Filtering
Contents
Introduction
By merging the user.csv and business.csv through the user_id and business_id in review, we get a complete X (predictor) matrix. From EDA we find that review score is strongly associated with some of the properties of users, or can be differented greatly on some attributed of restaurants. Therefore, we decide to build content filtering models, including linear regression, ridge regression, logistic regression and random forest regressor.
Content filtering models
Feature Selection
Before building the model, we preprocess the data by dropping certain uncorrelated variables, such as longitutde, latitude and postal code, as well as some string varibles, such as names, friends and so on. We deal with the missing values with imputation. Also, we didn’t include all the over 100 variables into consideration, because some of them don’t have strong and clear relationships with review score but increase the multicollinearity and sparsity of predictor matrix.
Instead, we pick 51 important predictors through EDA, which shows some relationships with review stars. For example, as shown in the EDA, review stars have various distributions on different dummy attributes of restaurant, such as different bestnight, music, food restriction, ambience and “good for” emphasis. Also, some of the categories in categorical attributes of restaurant show different patterns with others. Instead of taking dummy, we group by the different pattern and encode the categories according to their effect on review stars based on EDA. For instance, for attribute “RestaurantAttire”, only “formal” appear a different pattern compared with other categories in the box plot. So we only encode it with 1 and other categories with 0. For properties of users, we include variables that shows strong relationships with review stars, such as users’average star, fans, review count etc.
Here we assume:
-
average ratings of user and restaurants are always available;
-
the average ratings in the user and business tables wouldn’t deviate a lot from the averages we learn from data in the training set; thus it would be valid to include average rating from 2 tables as features in our model.
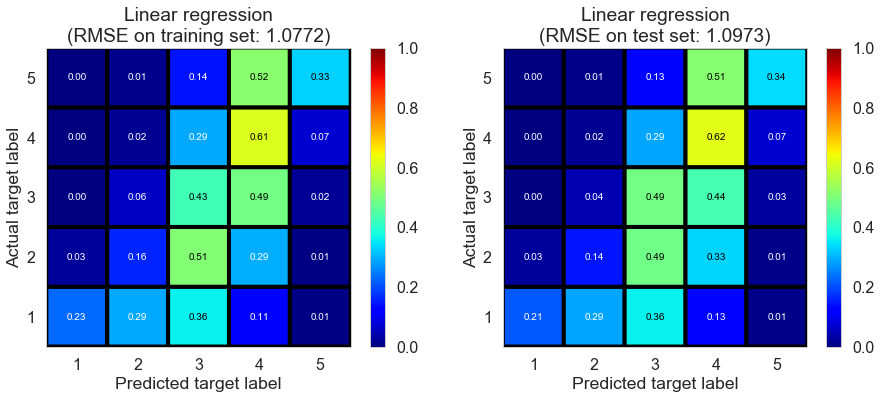
Linear regression
First of all, we perform general OLS to have a preliminary understanding of content filtering. Linear Regression result already indicates a great performance on test set compared with Baseline (Regression) model. Similar criterion values on both training and test set means including more attributes and using content filtering could fix overfitting well. In the following, we would implement certain models we learn from class to see if we could improve it.
| model | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Linear regression | 0.028 | 1.0772 | 1.0973 | 0.4341 | 0.4279 |
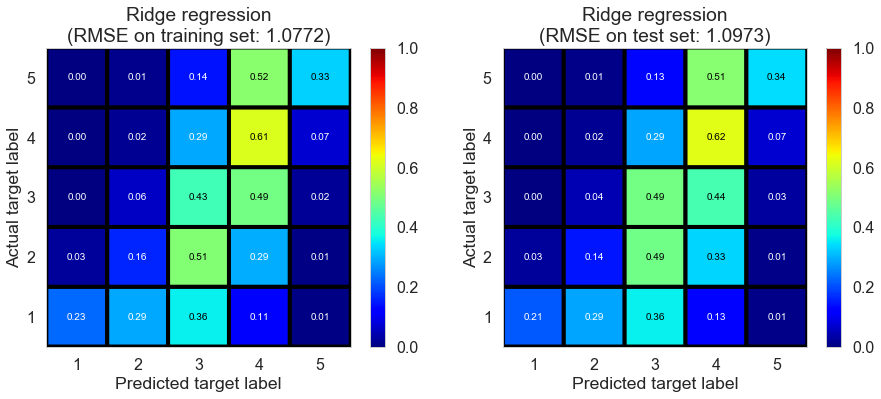
Ridge regression
| model | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Ridge regression | 0.064 | 1.0772 | 1.0973 | 0.4341 | 0.4279 |
Lasso regression
| model | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Lasso regression | 0.256 | 1.0786 | 1.0961 | 0.4326 | 0.4291 |
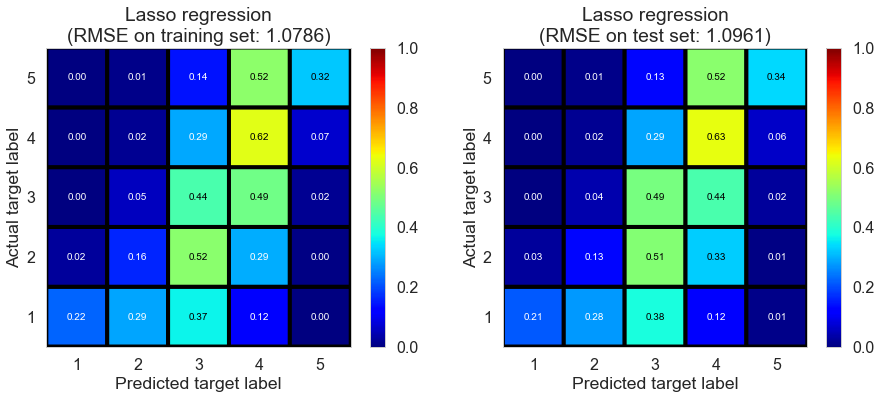
Regression with regularization doesn’t seem to improve a lot from OLS. Reason might be we already select important predictors. In fact, we try to use the complete predictors matrix (over 100 predictors) and try with RidgeCV/LassoCV. Results seem to be even worse. Manually selecting predictors might be better in interpretation and prediction. So in the following we keep using the selected predictor matrix rather than keep trying dimension reduction model such as stepwise/PCA.
Logistic regression
| model | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Logistic regression | 2.6832 | 1.3889 | 1.4052 | 0.0591 | 0.0618 |
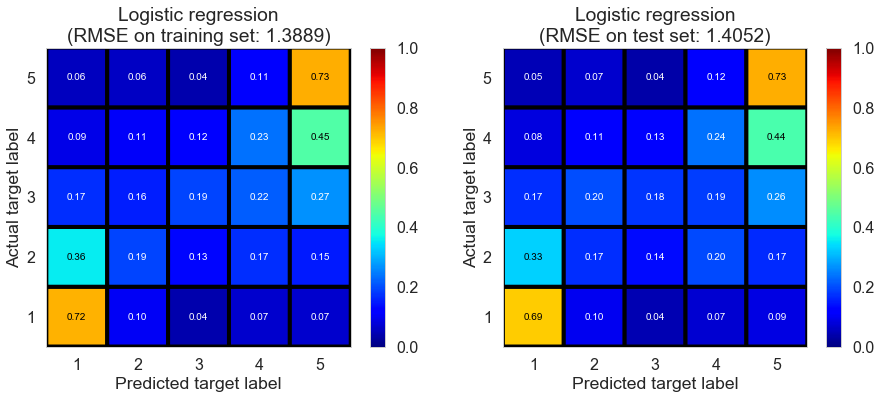
Besides regression model, we could also implement classification model. Here we try logistic regression with cross validation. Classification accuracy seem to improve compared with regression model, but RMSE get worse on both training and test set. As a matter of fact, we consider RMSE as a more important assessment because we had better not to punish at the same scale between predicting 5 as 1 and predicitng 5 as 4. This also explains why classification model doesn’t work as well as regression model due to the same punishment scale in loss function. So we no longer consider other classification models such as SVM etc.
Random forest regressor
We come back to regression model and try random forest regressor model. We choose appropriate parameters, including n_estimator and max_depth, through cross validation (GridSearchCV). Results show that this model performs better in RMSE and $R^2$ on both training and test set. Therefore, it provides us with some ideas on implementing ensemble models.
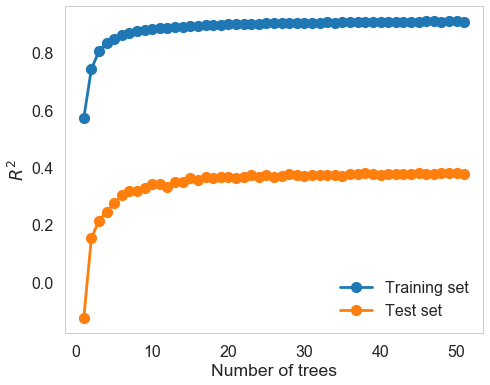
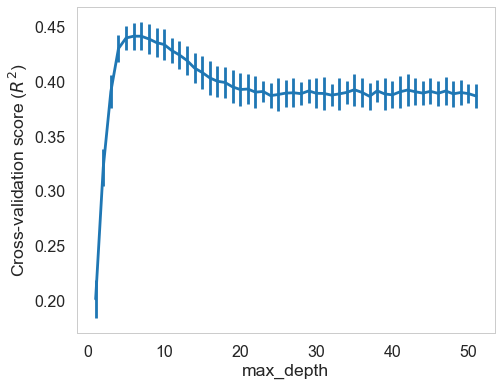
| model | fitting time (s) | train RMSE | test RMSE | train $R^2$ | test $R^2$ |
|---|---|---|---|---|---|
| Random forest | 1.1121 | 1.0265 | 1.0858 | 0.486 | 0.4398 |
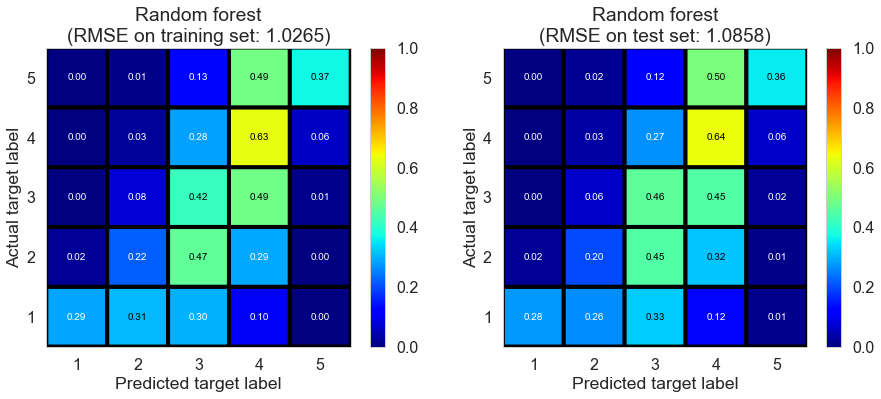
Potential Drawbacks
We investigated the significance of each predictor in the linear regression model, and found something fishy.
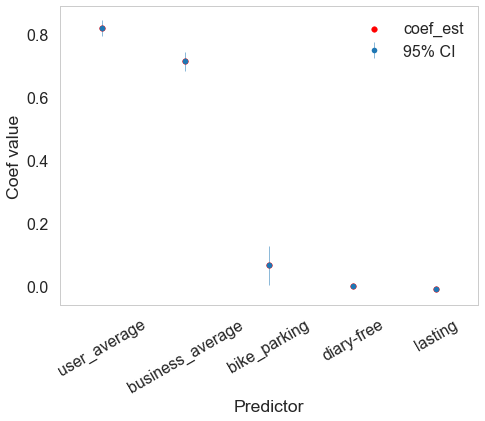
The assumption to include average stars as features might be fishy.
-
According to the following graph of importance of coefficients, 5 out of our 51 predictors in the model are significant / important: users’ average stars, restaurants’ average stars, restaurants’ bike parking, restaurants’ food restriction is diary-free, and years users started to use yelp. We don’t feel surprise to see the first two predictors since they play a main role in all of our models. In addition, the other predictors with coefficients slightly higher than 0 are also apparent indicators of high review score according to EDA. So the most important variables in this model are users’ average stars and restaurants’ average stars.
-
However, a majority of users or restaurants have only sent / received one review score. Therefore, when we make prediction based on these predictors, they are not always available.
-
Also, it the amount of review stars that users our restaurants have only sent / received is small, then the known average ratings in practice might be different from the average rating in the current two tables. Therefore, it might not be reasonable to directly using the average ratings in the two tables as the average ratings features we want.