Keywords: variance reduction | stratification | | Download Notebook
Contents
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
print("Finished Setup")
Finished Setup
The key idea in stratification is to split the domain on which we wish to calculate an expectation or integral into strata. Then, on each of these strata, we calculate the sub-integral as an expectation separately, using whatever method is appropriate for the stratum, and which gives us the lowest variance. These expectations are then combined together to get the final value.
In other words we can achieve better sampling in needed regions by going away from a one size fits all sampling scheme. One way to think about it is that regions with higher variability might need more samples, while not-so-varying regions could make do with less.
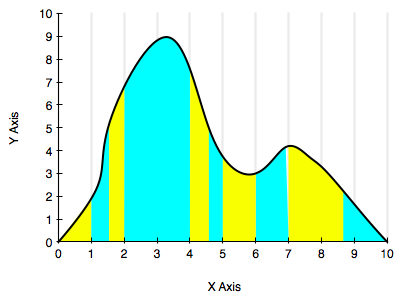
The diagram below illustrates this a bit. One could stratify by staying on the given grid, but the blue and yellow strata we have chosen might be better.
Why does stratification decrease variance?
Intuitively, smaller samples have less variance. And stratification lets us do designer sampling in the strata. But lets do the math…
Start by considering a one-dimensional expectation, over some region $D$ (could be [0,1]):
where $f(x)$ is a pdf normalized over the support D.
We’ll use the notation $\hat{\mu}$ to refer to a monte-carlo sample average. The hat ($^$) denotes that it is an estimator of $\mu$, the “population” average (you could think of the infinite limit as the population).
Then:
Here $E_R[.]$ is the expectation with respect to the sampling (or replications or bootstrap) distribution.
Now, instead of taking $N$ samples, we break the interval into $M$ strata and take $n_j$ samples for each strata $j$, such that $N=\sum_j n_j$.
Define the probability of being in region $D_j$ as $p_j$. Then this must be:
.
We can define a re-normalized pdf in the $j$th strata then as:
.
Then
where
is the expectation value under pdf $f_j$ of $h(x)$ in region $D_j$.
We can estimate this with monte-carlo by:
Let us now define the stratified estimator of the overall expectation
Taking the expectation with respect to the sampling distribution then gives us:
and thus $\hat{\mu_s}$ is an unbiaded estimator of $\mu$. Yay! We are on the right track.
But what about the variance?
where
is the “population variance” of $h(x)$ with respect to pdf $f_j(x)$ in region of support $D_j$.
How does this variance compare to the variance of the standrd Monte Carlo estimator $\hat{\mu}$? Lets calculate this.
where $\sigma^2$ is the population variance of $h(x)$ on all of $D$ with respect to pdf $f(x)$.
The integral on the right can be substituted for using the formula for $\sigma_j$ above and we get:
Now note that we found:
If we assume (a ok assumption as it allocates samples to the strata on the probability of being there but not based on the variance) that
we get:
which is the stratified variance plus a quantity that can be be shown to be positive by the cauchy schwartz equality.
Example
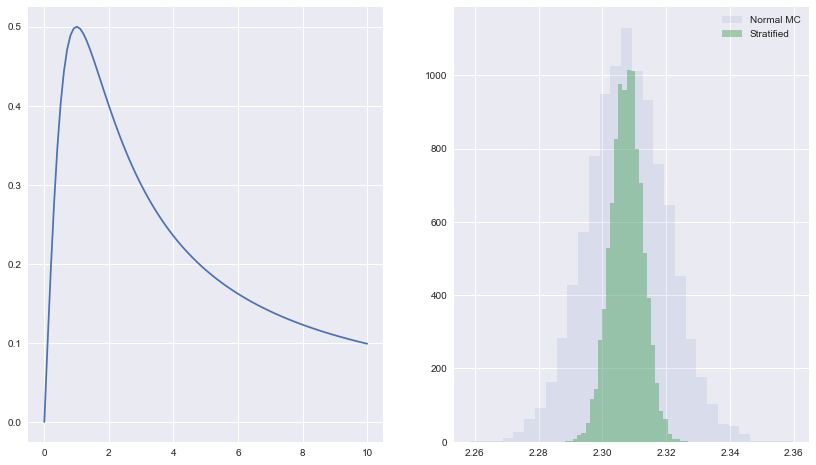
For a one-dimensional application we take $ x/(x^2+1)$ and integrate from $[0,1]$. We break $[0,10]$ into $M$ strata and for each stratum, take $N/M$ samples with uniform probability distribution. Compute the average within each stratum, and then calculate the overall average.
plt.figure(figsize=[14,8])
Y = lambda x: x/(x**2+1.0);
intY = lambda x: np.log(x**2 + 1.0)/2.0;
## Ploting the original functions
plt.subplot(1,2,1)
x = np.linspace(0,10,100)
plt.plot(x, Y(x), label=u'$x/(x**2+1)$')
N= 10000
Ns = 10 # number of strate
xmin=0
xmax =10
# analytic solution
Ic = intY(xmax)-intY(xmin)
Imc = np.zeros(N)
Is = np.zeros(N)
for k in np.arange(0,N):
Umin=0
Umax =10
# First lets do it with mean MC method
U = np.random.uniform(low=Umin, high=Umax, size=N)
Imc[k] = (Umax-Umin)* np.mean(Y(U))
#stratified it in Ns regions
step = (Umax-Umin )/Ns
Umin = 0
Umax = step
Ii = 0
for reg in np.arange(0,Ns):
x = np.random.uniform(low=Umin, high=Umax, size=N//Ns);
Ii = Ii+(Umax-Umin)* np.mean(Y(x))
Umin = Umin + step
Umax = Umin + step
Is[k] = Ii
plt.subplot(1,2,2)
plt.hist(Imc,30, histtype='stepfilled', label=u'Normal MC', alpha=0.1)
plt.hist(Is, 30, histtype='stepfilled', label=u'Stratified', alpha=0.5)
plt.legend()
<matplotlib.legend.Legend at 0x111b00cf8>