Keywords: normal distribution | multivariate normal | marginal | conditional | priors | correlation | covariance | kernel | posterior | posterior predictive | gaussian process | regression | empirical bayes | type-2 mle | pymc3 | inference | Download Notebook
Contents
- Recall:Definition of Gaussian Process
- Hyperparameter learning: Emprical Bayes or MCMC
- Fitting a model using pymc3
- Where are GPs used?
%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn as sns
sns.set_style("whitegrid")
sns.set_context("poster")
import pymc3 as pm
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.model_selection import train_test_split
Recall:Definition of Gaussian Process
So lets assume we have this function vector $ f=(f(x_1),…f(x_n))$. If, for ANY choice of input points, $(x_1,…,x_n)$, the marginal distribution over f:
is multi-variate Gaussian, then the distribution $P(f)$ over the function f is said to be a Gaussian Process.
We write a Gaussian Process thus:
where the mean and covariance functions can be thought of as the infinite dimensional mean vector and covariance matrix respectively.
By this we mean that the function $f(x)$ is drawn from a gaussian process with some probability. (It is worth repeating that a Gaussian Process defines a prior distribution over functions.) Once we have seen some data, this prior can be converted to a posterior over functions, thus restricting the set of functions that we can use based on the data.
The consequence of the finite point marginal distribution over functions being multi-variate gaussian is that any $m$ observations in an arbitrary data set, $y = {y_1,…,y_n=m}$ can always be represented as a single point sampled from some $m$-variate Gaussian distribution. Thus, we can work backwards to ‘partner’ a GP with a data set, by marginalizing over the infinitely-many variables that we are not interested in, or have not observed.
It is often assumed for simplicity that the mean of this ‘partnered’ GP is zero in every dimension. Then, the only thing that relates one observation to another is the covariance function $k(x_i, x_j)$.
There are many choices of covariance functions but a popular choice is the ‘squared exponential’,
where $\sigma_f^2$ is the maximum allowable covariance (or amplitude) and $l$ is the distance in the independent variable between $x_i$ and $x_j$. Note that this is a function solely of the independent variable, rather than the dependent one i.e. the only thing that impacts the corvariance function is the distances between each set of points.
Thus, it is the covariance function that dictates if small length scales will be more likely, and large ones will be less, for example, and thus that wiggly functions are more probable, or that more rather than less samples drawn from the GP will be wiggly.
x_pred = np.linspace(0, 10, 1000)
Calculate covariance based on the kernel
xold=np.arange(0,10,0.5)
xtrain, xtest = train_test_split(xold)
xtrain = np.sort(xtrain)
xtest = np.sort(xtest)
print(xtrain, xtest)
[ 0.5 1. 1.5 2. 3.5 4. 4.5 5. 5.5 7. 7.5 8. 8.5 9. 9.5] [ 0. 2.5 3. 6. 6.5]
At this point lets choose a regression function
"""The function to predict."""
def f(x):
return x**.5*np.sin(x)
plt.plot(xold, f(xold), 'o');
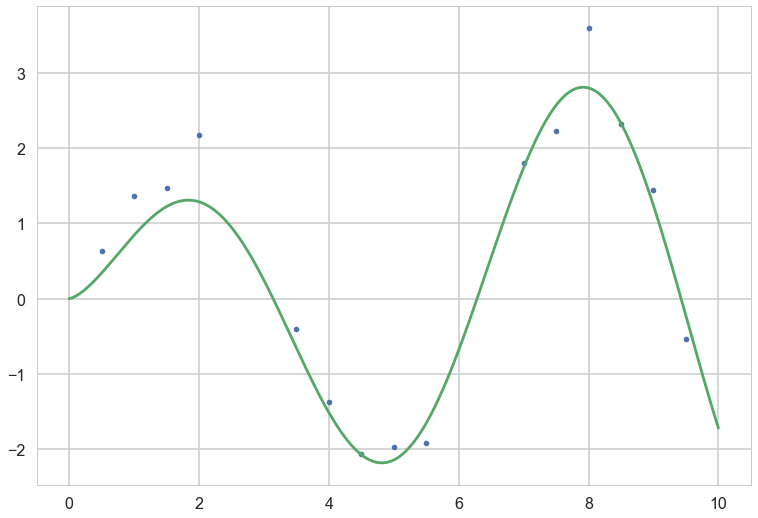
# Instantiate a Gaussian Process model
sigma_noise=0.4
noise = np.random.normal(0, sigma_noise, xtrain.shape[0])
ytrain = f(xtrain) + noise
plt.plot(xtrain, ytrain,'.')
plt.plot(x_pred, f(x_pred));
Hyperparameter learning: Emprical Bayes or MCMC
Above we very arbitrarily chose the parameters for the GP. In a bayesian context, these are parameters of our function prior, or they are hyperpriors. In analogy with mixtures, or hierarchical models, one way of obtaing the parameters would be to write out the joint distribution and do MCMC via a MH or Gibbs sampler. This is complex, but doable by setting priors on the amplitude and length scales of the kernel and the observational noise.
The full MCMC approach can get expensive in the limit of many training points, (indeed the matrix inversion must be done at each gibbs step). Still that is better than nothing since the training size is the dimensionality the infinite-dimensional problem has been reduced to.
We do this MCMC using the marginaly likelihood, because, after all, we want to marginalize over our “infinite set” of functions.
We could also use type-2 maximum likelihood or empirical bayes, and maximize the marginal likelihood.
The Marginal likelihood given a GP prior and a gaussian likelihood is: (you can obtain this from the properties of gaussians and their integrals)
where K is the covariance matrix obtained from evaluating the kernel pairwise at allpoints of the training set $X$.
The first term is a constant, the second is a model complexity term, and the third term is a quadratic form of the data. To understand the tradeoff between the data and complexity term, let us consider a squared exponential kernel in 1 dimension.
Holding the amplitude parameter fixed, lets vary the length parameter. For short length scales, the covariance is very wiggly, and thus 1 only near the diagonal. On the other hand, for large length scales, reasonably separated points are not different, and the covariance is close to 1 throughout.
Thus for shorter length scales, the model complexity term is large (the determinant is a product of diagonal terms). The fit will be very good. For longer length scales, the model complexity term will be small, as the matrix will be all ones. The fit will be poor. This corresponds to our general understanding of bias and variance: a long length scale imposes a very unwiggly, line like model, which will underfit, where as a model with a short length scale will have many wiggles, and thus possibly overfit.
To find the empirical bayes estimates of the hyperparameters, we will differentiate with respect to the hyperparameters, and set the derivatives to zero. Note that the noise variance can be added to the prior covariance hyperparameters, as is usual in the bayesian case.
Since the marginal likelihood is not convex, it can have local minima.
Since this is a ‘frequentist’ optimization in a bayesian scenario, dont forget to crossvalidate or similar to get good parameter estimates.
Below we carry out the MCMC procedure using pymc3, and MLE for the marginal likelihood using sklearn.
Fitting a model using pymc3
At this point, you might be wondering how to do Bayesian inference in the case of GPs. After all, to get posteriors on the hyperparameters we have to marginalize over functions, or equivalently infinite parameters.
The answer is something you might have not seen until now, but something which as always an option if the marginal likelihood integrals are analytic. Instead of optimizing the marginal likelihood, simply set up the bayesian problem as a hyperparameter posterior estimation problem. And in GPs, the marginal likelihood is simply Gaussian.
pymc3 lets us do that. See:
with pm.Model() as model:
# priors on the covariance function hyperparameters
#l = pm.Gamma('l', alpha=2, beta=1)
l = pm.Uniform('l', 0, 10)
# uninformative prior on the function variance
s2_f = pm.HalfCauchy('s2_f', beta=10)
# uninformative prior on the noise variance
s2_n = pm.HalfCauchy('s2_n', beta=5)
# covariance functions for the function f and the noise
f_cov = s2_f**2 * pm.gp.cov.ExpQuad(1, l)
mgp = pm.gp.Marginal(cov_func=f_cov)
y_obs = mgp.marginal_likelihood('y_obs', X=xtrain.reshape(-1,1), y=ytrain, noise=s2_n, is_observed=True)
with model:
marginal_post = pm.find_MAP()
logp = -26.248, ||grad|| = 0.0087801: 100%|██████████| 24/24 [00:00<00:00, 458.58it/s]
marginal_post
{'l': array(1.438132008790354),
'l_interval__': array(-1.7839733342616466),
's2_f': array(2.047500439200898),
's2_f_log__': array(0.7166197512509975),
's2_n': array(0.3465300514941838),
's2_n_log__': array(-1.0597857354139522)}
with model:
#step=pm.Metropolis()
trace = pm.sample(10000, tune=2000, nuts_kwargs={'target_accept':0.85})
#trace = pm.sample(10000, tune=2000, step=step)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [s2_n_log__, s2_f_log__, l_interval__]
100%|██████████| 12000/12000 [02:48<00:00, 71.32it/s]
#trace = trace[5000:]
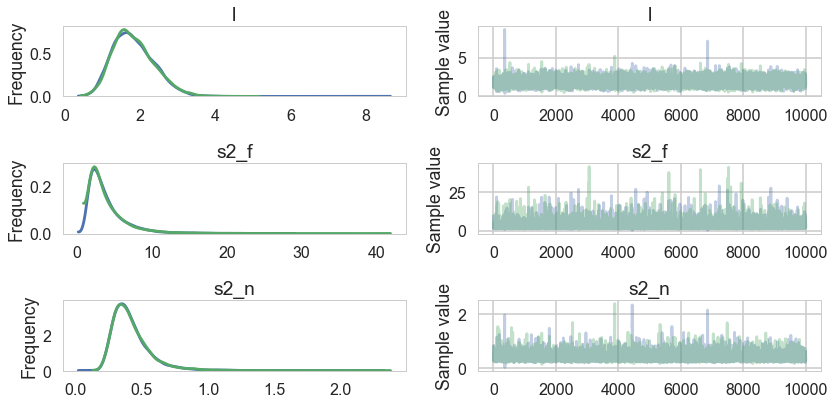
pm.summary(trace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| l | 1.839777 | 0.554045 | 0.005806 | 0.863758 | 2.920602 | 6893.0 | 1.000072 |
| s2_f | 3.935668 | 2.852325 | 0.033807 | 0.989995 | 9.194924 | 5846.0 | 0.999956 |
| s2_n | 0.421285 | 0.150123 | 0.001636 | 0.209725 | 0.706188 | 7745.0 | 0.999957 |
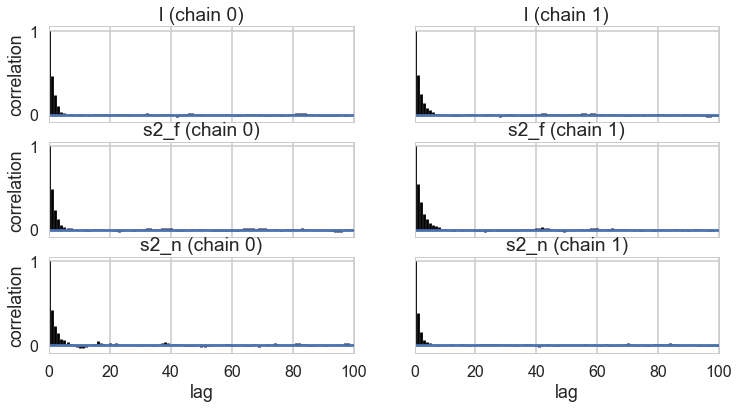
pm.autocorrplot(trace);
df = pm.trace_to_dataframe(trace)
df.corr()
| l | s2_f | s2_n | |
|---|---|---|---|
| l | 1.000000 | 0.751530 | -0.058854 |
| s2_f | 0.751530 | 1.000000 | -0.105919 |
| s2_n | -0.058854 | -0.105919 | 1.000000 |
pm.traceplot(trace, varnames=['l', 's2_f', 's2_n']);
sns.kdeplot(trace['s2_f'], trace['l'])
<matplotlib.axes._subplots.AxesSubplot at 0x154553dd8>
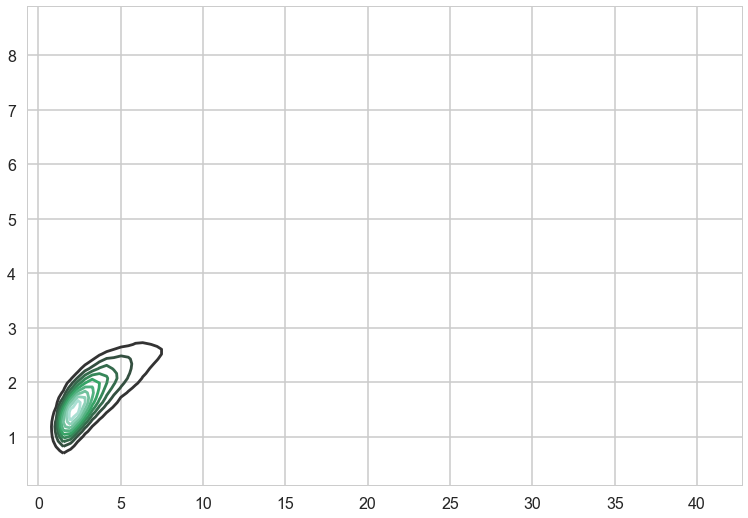
We can get posterior predictive samples usingsample_ppc, except that this being GPs, we will get back posterior predictive functions, not just parameter traces.
with model:
fpred = mgp.conditional("fpred", Xnew = x_pred.reshape(-1,1), pred_noise=False)
ypred = mgp.conditional("ypred", Xnew = x_pred.reshape(-1,1), pred_noise=True)
gp_samples = pm.sample_ppc(trace, vars=[fpred, ypred], samples=200)
100%|██████████| 200/200 [00:22<00:00, 8.98it/s]
gp_samples['ypred'].shape
(200, 1000)
meanpred = gp_samples['fpred'].mean(axis=0)
meanpred.shape
(1000,)
gp_samples['ypred'][0].shape
(1000,)
with sns.plotting_context("poster"):
[plt.plot(x_pred, y, color="gray", alpha=0.2) for y in gp_samples['fpred'][::5,:]]
# overlay the observed data
plt.plot(x_pred[::10], gp_samples['ypred'][123,::10], '.', color="green", label="noisy realization")
plt.plot(xtrain, ytrain, 'ok', ms=10, label="train pts");
plt.plot(x_pred, f(x_pred), 'r', ms=10, label="actual");
plt.plot(x_pred, meanpred, 'b', ms=10, label="predicted");
plt.xlabel("x");
plt.ylabel("f(x)");
plt.title("Posterior predictive distribution");
plt.xlim(0,10);
plt.legend();
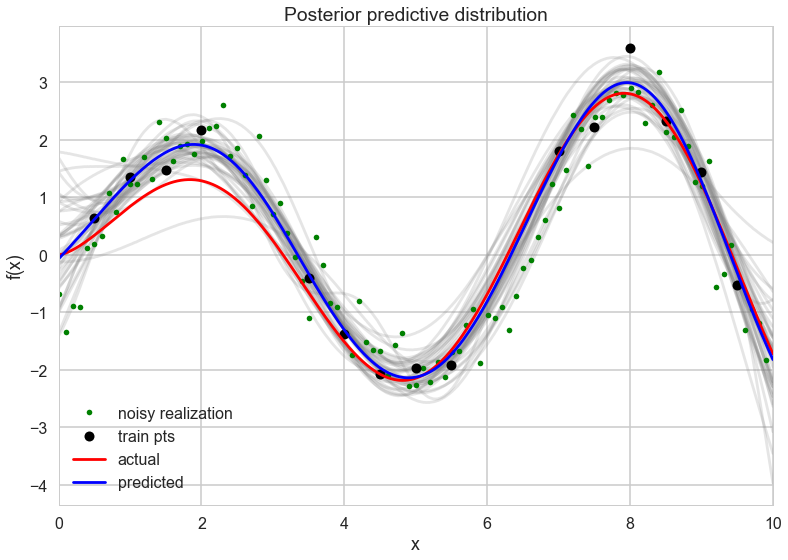
Where are GPs used?
- geostatistics with kriging, oil exploration
- spatial statistics
- as an interpolator (0 noise case) in weather simulations
- they are equivalent to many machine learning models such as kernelized regression, SVM and neural networks (some)
- ecology since model uncertainty is high
- they are the start of non-parametric regression
- time series analysis (see cover of BDA)
- because of the composability of kernels, in automatic statistical analysis (see the automatic statistician)