Keywords: sampling | rejection sampling | integration | lotus | law of large numbers | monte-carlo | expectations | Download Notebook
Contents
Contents
Monte Carlo
The basic idea of a Monte Carlo Algorithm is to use randomness to solve what is often a deterministic problem. In this course, we’ll study their application in 3 different places: optimization, integration, and obtaining draws from a probability distribution. These uses are often intertwined: optimization is needed to find modes of distributions and integration to find expectations.
Wikipedia has a facinating bit of history on the subject, from which I quote:
The first thoughts and attempts I made to practice [the Monte Carlo Method] were suggested by a question which occurred to me in 1946 as I was convalescing from an illness and playing solitaires. The question was what are the chances that a Canfield solitaire laid out with 52 cards will come out successfully? After spending a lot of time trying to estimate them by pure combinatorial calculations, I wondered whether a more practical method than “abstract thinking” might not be to lay it out say one hundred times and simply observe and count the number of successful plays. This was already possible to envisage with the beginning of the new era of fast computers, and I immediately thought of problems of neutron diffusion and other questions of mathematical physics, and more generally how to change processes described by certain differential equations into an equivalent form interpretable as a succession of random operations. Later [in 1946], I described the idea to John von Neumann, and we began to plan actual calculations. –Stanislaw Ulam
Being secret, the work of von Neumann and Ulam required a code name.[citation needed] A colleague of von Neumann and Ulam, Nicholas Metropolis, suggested using the name Monte Carlo, which refers to the Monte Carlo Casino in Monaco where Ulam’s uncle would borrow money from relatives to gamble.
Estimate the area of a unit circle
To understand how randomness can be brought to bear upon solving deterministic problems, consider a very simple example: the value of $\pi$. If you could uniformly generate random numbers on a square, you could ask, how many of these numbers would fall inside a unit circle embedded in and touching the midpoints of the sides of the square. This ratio would be
#area of the bounding box
box_area = 4.0
#number of samples
N_total = 10000.0
#drawing random points uniform between -1 and 1
X = np.random.uniform(low=-1, high=1, size=N_total)
Y = np.random.uniform(low=-1, high=1, size=N_total)
# calculate the distance of the points from the center
distance = np.sqrt(X**2+Y**2);
# check if point is inside the circle
is_point_inside = distance<1.0
# sum up the hits inside the circle
N_inside=np.sum(is_point_inside)
# estimate the circle area
circle_area = box_area * N_inside/N_total
# some nice visualization
plt.scatter(X,Y, c=is_point_inside, s=5.0, edgecolors='none', cmap=plt.cm.Paired)
plt.axis('equal')
plt.xlabel('x')
plt.ylabel('y')
# text output
print("Area of the circle = ", circle_area)
print("pi = ", np.pi)
//anaconda/envs/py35/lib/python3.5/site-packages/ipykernel/__main__.py:8: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
//anaconda/envs/py35/lib/python3.5/site-packages/ipykernel/__main__.py:9: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
Area of the circle = 3.1344
pi = 3.141592653589793
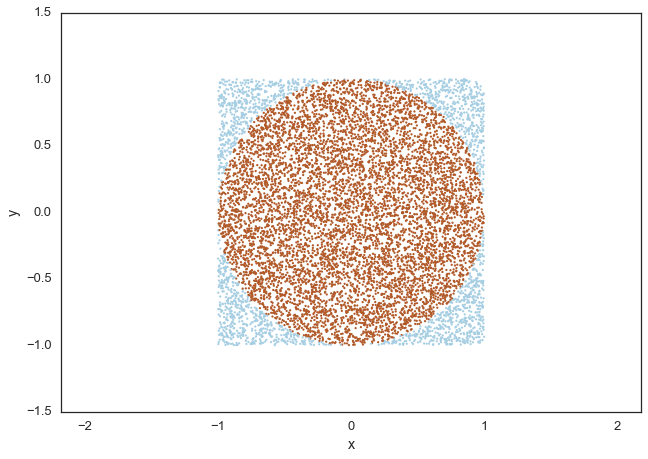
Intuitively, one might expect our estimate of $\pi$ to get better as we draw more and more samples: we are covering the areas with samples much better when we do that.
Lets try to think about the mathematics in the intuition which tells us that we can calculate $\pi$ in this way.
The area of the circle C can be obtained by computing a double integral like so:
where $I_{\in C} (x, y) = 1$ if $x,y \in C$ and $I_{\in C}(x) = 0$ if $x,y \notin C$.
This is basically adding up all the small area elements inside the circle.
Remember from the LOTUS:
and then we can use the law of large numbers to calculate this expectation and thus this probability.
The relationship of the expression all the way on the left to that all the way on the right is simply the law of large numbers we saw before. This is a distribution independent statement.
But the critical thing to notice is that:
once we choose a uniform distribution. Here $V$ is the support, the normalizing factor..here 4. The expectation from the law of large numbers comes from a sequence of identically distributed bernoullis (independent of $f$ which here is uniform). All we have to do, is just like before in the law, count the frequency of samples inside.
Hit or miss method
This simple scenario of inside-or-outside can be used as a general (but poor, as missing increases exponentially with dimension) way to use the generation of samples to carry out integration
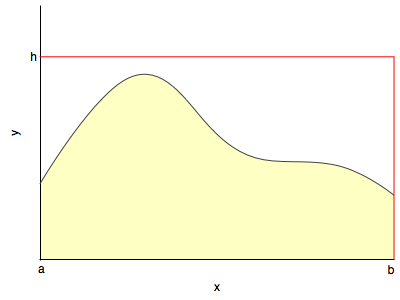
You basically generate samples from a uniform distribution with support on the rectangle and see how many fall below $y(x)$ at a specific x.
This is the basic idea behind rejection sampling