Keywords: variational inference | elbo | kl-divergence | normal distribution | mean-field approximation | advi | optimization | sgd | minibatch sgd | Download Notebook
Contents
- From CAVI to Stochastic CAVI to ADVI
- ADVI in pymc3: approximating a gaussian
- ADVI: what does it do?
- Demonstrating ADVI in pymc3
%matplotlib inline
import numpy as np
import scipy as sp
import matplotlib as mpl
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.width', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.notebook_repr_html', True)
import seaborn as sns
sns.set_style("whitegrid")
sns.set_context("poster")
import pymc3 as pm
From CAVI to Stochastic CAVI to ADVI
One of the challenges of any posterior inference problem is the ability to scale. While VI is faster than the traditional MCMC, the CAVI algorithm described above fundamentally doesn’t scale as it needs to run through the entire dataset each iteration. An alternative that is sometimes recommended is the Stochastic CAVI that uses gradient-based optimization. Using this approach, the algorithm only requires a subsample of the data set to iteratively optimize local and global parameters of the model.
Stochastic CAVI is specifically used for conditionally conjugate models, but the ideas from it are applicable outside: the use of gradient (for gradient ascent) and the use of SGD style techniques: minibatch or fully stochastic.
Finally, we have seen how to implement SGD in Theano, and how pymc3 uses automatic differentiation under the hood to provide gradients for its NUTS sampler. This idea is used to replace CAVI with an automatically-calculated gradient-ascent algorithm, with stochastic updates that allow us to scale by not requiring the use of the complete dataset at each iteration.
ADVI in pymc3: approximating a gaussian
data = np.random.randn(100)
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1, testval=0)
sd = pm.HalfNormal('sd', sd=1)
n = pm.Normal('n', mu=mu, sd=sd, observed=data)
advifit = pm.ADVI( model=model)
advifit.fit(n=50000)
Average Loss = 165.04: 100%|██████████| 50000/50000 [00:39<00:00, 1277.26it/s]
Finished [100%]: Average Loss = 165.04
<pymc3.variational.approximations.MeanField at 0x102ed5518>
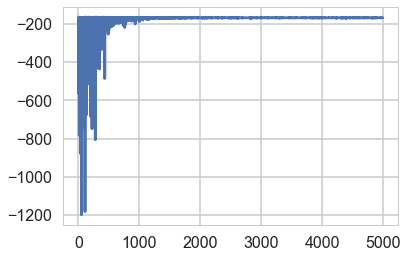
elbo = -advifit.hist
plt.plot(elbo[::10]);
advifit.approx.shared_params, type(advifit.approx.shared_params)
({'mu': mu, 'rho': rho}, dict)
advifit.approx.mean.eval(), advifit.approx.std.eval()
(array([ 0.01136291, 0.19029473]), array([ 0.13027711, 0.0771372 ]))
m = advifit.approx.mean.eval()[0]
s = advifit.approx.std.eval()[1]
m,s
(0.011362907299281614, 0.077137198012325089)
sig = np.exp(advifit.approx.mean.eval()[1])
sig
1.2096060539497815
trace = advifit.approx.sample(10000)
pm.summary(trace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | |
|---|---|---|---|---|---|
| mu | 0.011175 | 0.129574 | 0.001208 | -0.238381 | 0.263709 |
| sd | 1.211072 | 0.094905 | 0.001004 | 1.021418 | 1.395402 |
pm.traceplot(trace)
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x1176ef320>,
<matplotlib.axes._subplots.AxesSubplot object at 0x117751240>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x1177235c0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x11780cc88>]], dtype=object)
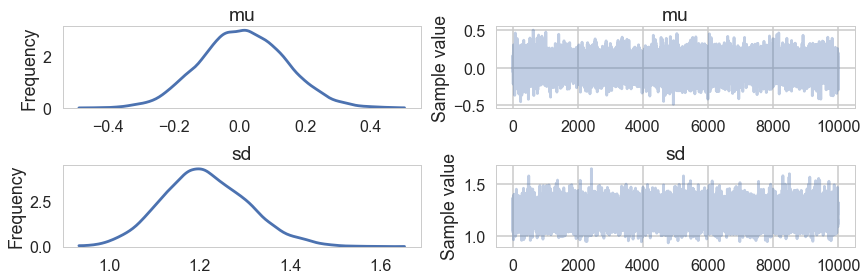
trace['mu'].mean(), trace['sd'].mean()
(0.011174712645382104, 1.2110722263923666)
pred = pm.sample_ppc(trace, 5000, model=model)
100%|██████████| 5000/5000 [00:01<00:00, 3262.40it/s]
with model:
step = pm.NUTS()
trace_nuts = pm.sample(5000, step)
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sd_log__, mu]
100%|██████████| 5500/5500 [00:03<00:00, 1395.17it/s]
pm.summary(trace_nuts)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| mu | 0.014962 | 0.120005 | 0.001224 | -0.214366 | 0.253263 | 10000.0 | 1.000006 |
| sd | 1.214682 | 0.088136 | 0.001033 | 1.043819 | 1.381650 | 8702.0 | 0.999922 |
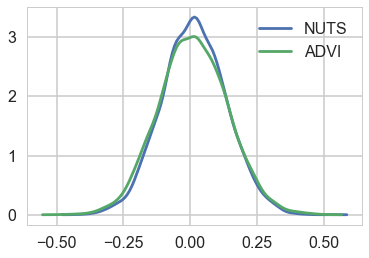
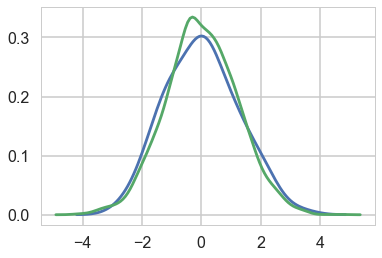
Comparing the mu parameter
sns.kdeplot(trace_nuts['mu'], label='NUTS')
sns.kdeplot(trace['mu'], label='ADVI')
plt.legend();
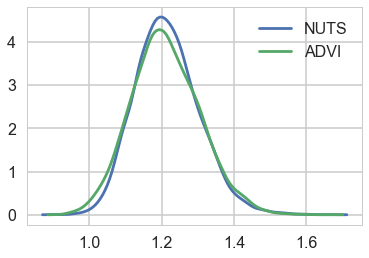
sns.kdeplot(trace_nuts['sd'], label='NUTS')
sns.kdeplot(trace['sd'], label='ADVI')
plt.legend();
Comparing the data to the posterior-predictive
sns.kdeplot(data)
sns.kdeplot(pred['n'])
<matplotlib.axes._subplots.AxesSubplot at 0x118b95198>
ADVI: what does it do?
Remember that in Variational inference, we decompose an aprroximate posterior in the mean-field approximation into a product of per-latent-variable posteriors. The approximate posterior is chosen from a pre-specified family of distributions to “variationally” minimize the KL-divergence (equivalently to maximize the ELBO) between itself and the true posterior.
This means that the ELBO must be painstakingly calculated and optimized with custom CAVI updates for each new model, and an approximating family chosen. If you choose to use a gradient based optimizer then you must supply gradients.
From the ADVI paper:
ADVI solves this problem automatically. The user specifies the model, expressed as a program, and ADVI automatically generates a corresponding variational algorithm. The idea is to first automatically transform the inference problem into a common space and then to solve the variational optimization. Solving the problem in this common space solves variational inference for all models in a large class.
Here is what ADVI does for us:
(1) The model undergoes transformations such that the latent parameters are transformed to representations where the ‘new” parameters are unconstrained on the real-line. Specifically the joint $p(x, \theta)$ transforms to $p(z, \eta)$ where $\eta$ is unconstrained. We then define the approximating density $q$ and the posterior in terms of these transformed variable and minimize the KL-divergence between the transformed densities. This is done for ALL latent variables so that all of them are now defined on the same space. As a result we can use the same variational family for ALL parameters, and indeed for ALL models, as every parameter for every model is now defined on all of R. It should be clear from this that Discrete parameters must be marginalized out.
![]()
Optimizing the KL-divergence implicitly assumes that the support of the approximating density lies within the support of the posterior. These transformations make sure that this is the case
(2) Ok, so now we must maximize our suitably transformed ELBO (the log full-data posterior will gain an additional term which is the determinant of the log of the Jacobian). Remember in variational inference that we are optimizing an expectation value with respect to the transformed approximate posterior. This posterior contains our transformed latent parameters so the gradient of this expectation is not simply defined.
What are we to do?
(3) We first choose as our family of approximating densities mean-field normal distributions. We’ll tranform the always positive $\sigma$ params by simply taking their logs.
The choice of Gaussians may make you think that we are doing a laplace (taylor series) approximation around the posterior mode, which is another method for approximate inference. This is not what we are doing here.
We still havent solved the problem of taking the gradient. Basically what we want to do is to push the gradient inside the expectation. For this, the distribution we use to calculate the expectation must be free of parameters we might compute the gradient with respect to.
So we indulge ourselves another transformation, which takes the approximate 1-D gaussian $q$ and standardizes it. The determinant of the jacobian of this transform is 1.
As a result of this, we can now compute the integral as a monte-carlo estimate over a standard Gaussian–superfast, and we can move the gradient inside the expectation (integral) to boot. This means that our job now becomes the calculation of the gradient of the full-data joint-distribution.
(4) We can replace full $x$ data by just one point (SGD) or mini-batch (some-$x$) and thus use noisy gradients to optimize the variational distribution. An adaptively tuned step-size is used to provide good convergence.
Demonstrating ADVI in pymc3
We wish to sample a 2D Posterior which looks something like below. Here the x and y axes are parameters.
cov=np.array([[1,0.8],[0.8,1]])
data = np.random.multivariate_normal([0,0], cov, size=1000)
sns.kdeplot(data, alpha=0.4);
plt.scatter(data[:,0], data[:,1], s=10, alpha=0.2)
<matplotlib.collections.PathCollection at 0x11c3838d0>
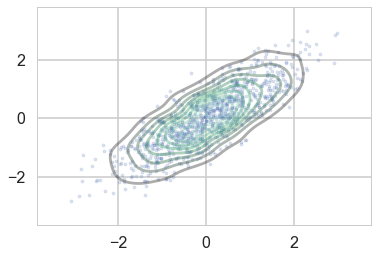
np.std(data[:,0]),np.std(data[:,1])
(1.0084225770477742, 1.010665277500306)
Ok, so we just set up a simple sampler with no observed data
import theano.tensor as tt
cov=np.array([[0,0.8],[0.8,0]], dtype=np.float64)
with pm.Model() as mdensity:
density = pm.MvNormal('density', mu=[0,0], cov=tt.fill_diagonal(cov,1), shape=2)
We try and retrieve the posterior by sampling
with mdensity:
mdtrace=pm.sample(10000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [density]
100%|██████████| 10500/10500 [00:18<00:00, 559.28it/s]
The number of effective samples is smaller than 25% for some parameters.
pm.traceplot(mdtrace);

We do a pretty good job:
plt.scatter(mdtrace['density'][:,0], mdtrace['density'][:,1], s=5, alpha=0.1)
<matplotlib.collections.PathCollection at 0x11d2a81d0>
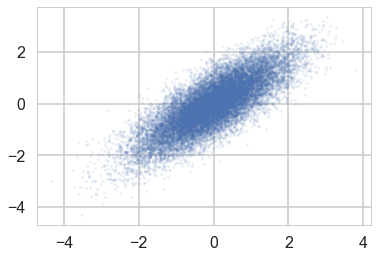
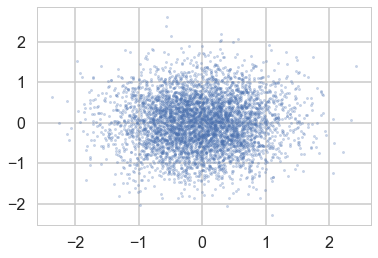
But when we sample using ADVI, the mean-field approximation means that we lose our correlation:
mdvar = pm.ADVI(model=mdensity)
mdvar.fit(n=40000)
Average Loss = 0.53523: 100%|██████████| 40000/40000 [00:48<00:00, 823.28it/s]
Finished [100%]: Average Loss = 0.53454
<pymc3.variational.approximations.MeanField at 0x11e4d1908>
plt.plot(-mdvar.hist[::10])
[<matplotlib.lines.Line2D at 0x11eb02518>]
samps=mdvar.approx.sample(5000)
plt.scatter(samps['density'][:,0], samps['density'][:,1], s=5, alpha=0.3)
<matplotlib.collections.PathCollection at 0x11f143908>
We’ll see how to use ADVI to fit mixture models in lab.