Keywords: entropy | maxent | binomial | normal distribution | statistical mechanics | Download Notebook
Contents
- Information and Entropy
- Entropy measures uncertainty
- Thermodynamic notion of Entropy
- Maximum Entropy (maxent)
- The importance of maxent
Contents
Information and Entropy
Imagine tossing a coin. If I knew the exact physics of the coin, the initial conditions of the tossing, I could predict deterministically how the coin would land. But usually, without knowing anything, I say by symmetry or by “long-run” experince that the odds of getting heads are 50%.
This reflects my minimal knowledge about this system. Without knowing anything else about the universe…the physics, the humidity, the weighting of the coin, etc..assuming a probability of 0.5 of getting heads is the most conservative thing I could do.
You can think of this as a situation with minimal information content.
It is a very interesting situation, however, when you think about this from the perspective of the multiple ways you could get half the coin tosses in a long run of coin tosses come up heads. There is only one way in which you can get all coin tosses come up heads. There are $n \choose n/2$ ways on the other hand in which you can get half heads! You can think of this situation being one of more states or events being consistent with a probability of heads of 0.5 than with a probability of 1.
By the same token, an election with a win probability of 0.99 isnt that interesting. A lot of information went into getting this probability presumably: polls, economic modelling, etc. But to get such certainty implies a greater determinism-to-randomness ratio in the process.
One can think of information as the reduction in uncertainty from learning an outcome
Clearly we need a measure of uncertainty so that we can quantify how much it has decreased.
Desiderata for a measure of uncertainty
- must be continuous so that there are no jumps
- must be additive across events or states, and must increase as the number of events/states increases
Entropy measures uncertainty
A function that satisfies these desiderata is the information entropy:
Thus the entropy is the average log probability of an event…
Example of the coin toss or Bernoulli variable
For $p=0$ or $p=1$ we must use L’Hospital’s rule: if we have the division of two limits as $0/0$ or $\infty/\infty$ then differentiate both the numerator and denominator and try again:
import math
p = np.linspace(0,1,100)
def h(p):
if p==1.:
ent = 0
elif p==0.:
ent = 0
else:
ent = - (p*math.log(p) + (1-p)* math.log(1-p))
return ent
plt.plot(p, [h(pr) for pr in p]);
plt.axvline(0.5, 0, 1,'r')
<matplotlib.lines.Line2D at 0x114147be0>
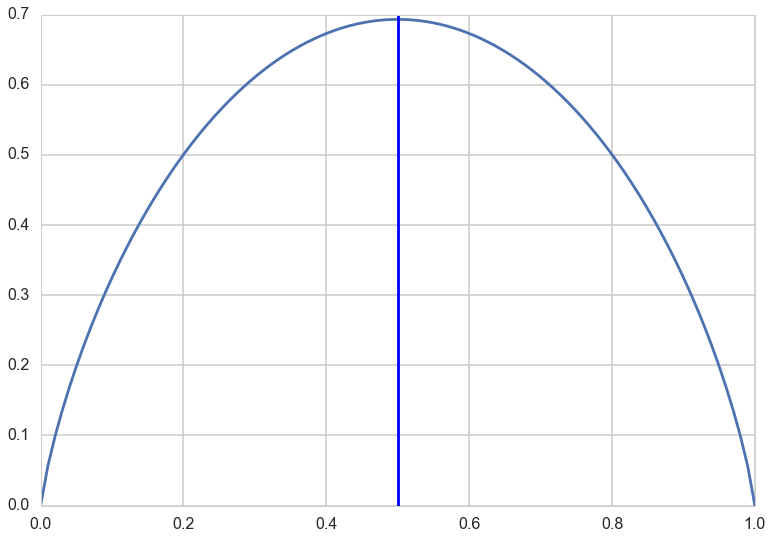
Thus you can see there is maximal uncertainty at 0.5.
Thermodynamic notion of Entropy
Imagine dividing $N$ objects amongst $M$ bins. One can think of this as stone tossing, where we toss N stones and see in which bin they land up. There is a distribution for this, ${p_i}$, of-course, so lets see what it is.
There are $N$ ways to fill the first bin, $N-1$ ways to fill the second, $N-2$ ways to fill the third, and so on…thus $N!$ ways. Since we dont distinguish the arrangement of objects in each bin we must divide bu the factorial of the bin amounts. If we then assume a uniform chance of landing in each bucket, then we just get the nultinomial distribution:
is called the multiplicity and the entropy is then defined as:
which is:
with a constant term removed.
.
Using Stirling’s approximation $log(N!) \sim Nlog(N) -N$ as $N \to \infty$ and where the fractions $n_i/N$ are held fixed:
Thus
If the probabilities of landing in each bucket are not equal, ie not uniform, then we can show:
This definition has origins in statistical mechanics. Entropy was first introduced in thermodynamics and then later interpreted as a measure of disorder: how many events or states can a system constrained to have a given enrgy have. A physicist calls a particular arrangement ${n_i} = (m_1, n_2, n_3,…,n_M)$ a microstate and the overall distribution of ${p_i}$, here the multinomial , a macrostate, with $W$ calledthe weight.
Maximum Entropy (maxent)
Maximum entropy is the notion of finding distributions consistent with constraints and the current state of our knowledge . In other words, what would be the least surprising distribution? The one with the least additional assumptions?
We can maximize
in the case of the ball and bin model above, by considering the langrange-multiplier enhanced, constraint enforcing entropy
This means that the $p_j$’s are all equal and thus must be $\frac{1}{M}$: thus the distribution with all $p$s equal maximizes entropy.
The distribution that can happen in the most ways is the one with the highest entropy, as we can see above.
Normal as maxent
The origin story of the gaussian itself is that many small effects add up to produce them. It is exactly the “many” aspect os these that makes the gaussian a maxent distribution. For every sequence that produces an unbalanced outcome(like a long string of heads), there are many more ways of producing a balanced outcome. In otherwords, there are so many microstates of the system that can produce the “peak” macrostates.
This is a plot from McElreath of a bunch of generalized normal distributions. with same mean and variance. The Gaussuan has the highest entropy, as we shall prove below.
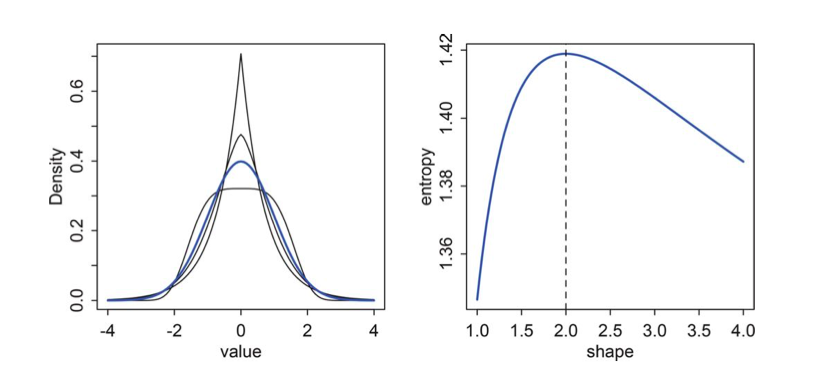
If you think about entropy increasing as we make a distribution flatter, you realize that the shape must come about because finite and equal variance puts a limit on how wide the distribution can be.
For a gaussian
No other distribution $q$ can have higher entropy than this, provided they share the same variance and mean.
To see this consider (note change in order, we are considering $\kld(q, p)$:
The second expectation here is the variance $\s igma^2$ on the assumption that $E_q[x] = \mu$.
Thus
Now as we have shown $\kld(q,p) >=0$. This means that $H(q,p) - H(q) >= 0$. Which then means that $H(p) - H(q) >= 0$ or $H(p) >= H(q)$. This means that the Gaussian has the highest entropy of any distribution with the same mean and variance.
See http://www.math.uconn.edu/~kconrad/blurbs/analysis/entropypost.pdf for details on maxent for distributions.
Binomial as Maxent
Information entropy increases as a probability distribution becomes more even. We saw that with the thermodynamic idea of entropy and the multinomial distribution.
Consider the situation when:
- only two outcomes (unordered) are possible.
- the process generating the outcomes is invariant in time, ie the expected value remains constant (over temporal or other subsequences)
Then it turns out that for these constraints, the maximum entropy distribution is the binomial. The binomial basically spreads probability out as evenly and conservatively as possible, making sure that outcomes that have many more ways they can happen have more probability mass. Basically the binomial figures the number of ways any possible sequence of data can be realized, which is what entropy does. Thus it turns out that likelihoods derived by such counting turn out to be maximum entropy likelihoods.
For binomial parameter $\lambda/n$:
Now, if $E_q[x] = \lambda$, our invariant expectation, we have $H(q,p) = H(p)$ as we get the same formula if we substitute $q=p$ to get the entropy of the binomial. In other words, $H(p) >= H(q)$ and we have shown the binomial has maximum entropy amongst discrete distributions with two outcomes and fixed expectations.
The importance of maxent
The most common distributions used as likelihoods (and priors) in modeling are those in the exponential family. The exponential family can be defined as having pmf or pdf:
Where $Z(\theta)$, also called the partition function, is the normalization.
For example, the univariate Gaussian Distribution can be obtained with:
Each member of the exponential family turns out to be a maximum entropy distribution subject to different constraints. These distributions are then used as likelihoods.
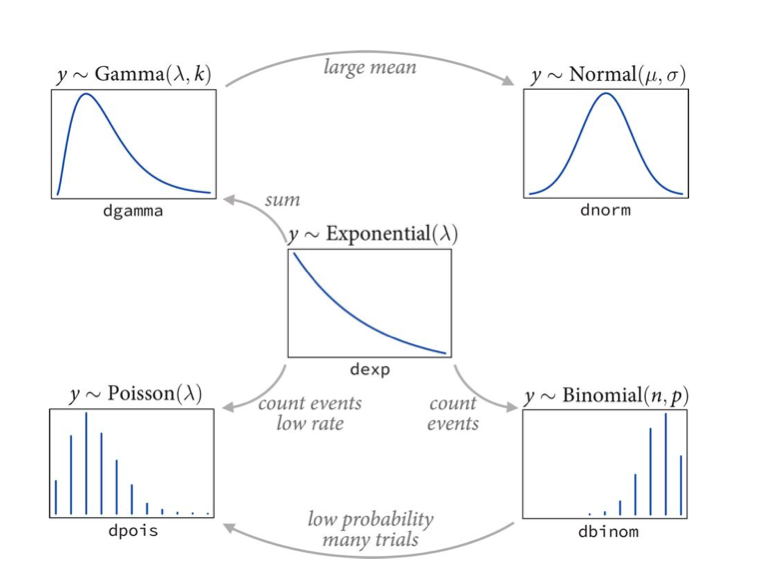
For example, the gamma distribution, which we shall see later, is maximum entropy amongst all distributions with the same mean and same average logarithm. The poisson distribution, used for low event rates, is maxent under similar conditions as the binomial as it is a special case of the binomial. The exponential distribution is maxent among all non-negative continuous distributions with the same average inter-event displacement. (In our births example, the inter-birth time).
We’ll talk more about these distributions when we encounter them, and when we talk about generalized linear models.
But here is the critical point. We will often choose a maximum entropy distribution as a likelihood . Information entropy ennumerates the number of ways a distribution can arise, after having fixed some assumptions. Thus, in choosing a MAXENT distribution as a likelihood, we choose a distribution that once the constraints has been met, does not contain any additional assumptions. It is thus the most conservative distribution we could choose consistent with our constraints.