Download Notebook
Contents
%matplotlib inline
import theano
import pymc3 as pm
import theano.tensor as T
import sklearn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from warnings import filterwarnings
from sklearn import datasets
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
sns.set_style('whitegrid')
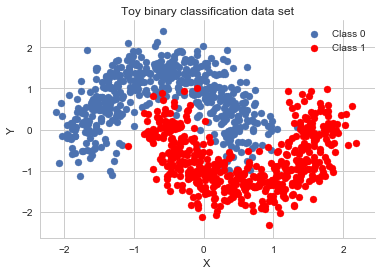
X, Y = make_moons(noise=0.2, random_state=0, n_samples=1000)
X = scale(X)
Y = Y.astype('float64')
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.5)
fig, ax = plt.subplots()
ax.scatter(X[Y==0, 0], X[Y==0, 1], label='Class 0')
ax.scatter(X[Y==1, 0], X[Y==1, 1], color='r', label='Class 1')
sns.despine(); ax.legend()
ax.set(xlabel='X', ylabel='Y', title='Toy binary classification data set');
X_train.shape
(500, 2)
def construct_nn(ann_input, ann_output):
n_hidden = 5
# Initialize random weights between each layer
init_1 = np.random.randn(X.shape[1], n_hidden)
init_2 = np.random.randn(n_hidden, n_hidden)
init_out = np.random.randn(n_hidden)
with pm.Model() as neural_network:
# Weights from input to hidden layer
weights_in_1 = pm.Normal('w_in_1', 0, sd=1,
shape=(X.shape[1], n_hidden),
testval=init_1)
# Weights from 1st to 2nd layer
weights_1_2 = pm.Normal('w_1_2', 0, sd=1,
shape=(n_hidden, n_hidden),
testval=init_2)
# Weights from hidden layer to output
weights_2_out = pm.Normal('w_2_out', 0, sd=1,
shape=(n_hidden,),
testval=init_out)
# Build neural-network using tanh activation function
act_1 = pm.math.tanh(pm.math.dot(ann_input,
weights_in_1))
act_2 = pm.math.tanh(pm.math.dot(act_1,
weights_1_2))
act_out = pm.math.sigmoid(pm.math.dot(act_2,
weights_2_out))
# Binary classification -> Bernoulli likelihood
out = pm.Bernoulli('out',
act_out,
observed=ann_output,
total_size=Y_train.shape[0] # IMPORTANT for minibatches
)
return neural_network
# Trick: Turn inputs and outputs into shared variables.
# It's still the same thing, but we can later change the values of the shared variable
# (to switch in the test-data later) and pymc3 will just use the new data.
# Kind-of like a pointer we can redirect.
# For more info, see: http://deeplearning.net/software/theano/library/compile/shared.html
ann_input = theano.shared(X_train)
ann_output = theano.shared(Y_train)
neural_network = construct_nn(ann_input, ann_output)
with neural_network:
nutstrace = pm.sample(2000, tune=1000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [w_2_out, w_1_2, w_in_1]
100%|██████████| 3000/3000 [03:52<00:00, 12.92it/s]
There were 232 divergences after tuning. Increase `target_accept` or reparameterize.
The acceptance probability does not match the target. It is 0.651692949328, but should be close to 0.8. Try to increase the number of tuning steps.
There were 120 divergences after tuning. Increase `target_accept` or reparameterize.
The acceptance probability does not match the target. It is 0.682274841411, but should be close to 0.8. Try to increase the number of tuning steps.
The gelman-rubin statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The estimated number of effective samples is smaller than 200 for some parameters.
pm.summary(nutstrace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| w_in_1__0_0 | 0.123930 | 1.330869 | 0.116547 | -2.460931 | 2.930068 | 9.0 | 1.137070 |
| w_in_1__0_1 | -0.493261 | 1.431399 | 0.130625 | -3.050534 | 2.414883 | 23.0 | 1.107352 |
| w_in_1__0_2 | -0.391219 | 1.359743 | 0.118412 | -2.887345 | 2.457370 | 51.0 | 0.999820 |
| w_in_1__0_3 | 0.265870 | 1.427571 | 0.128061 | -2.439405 | 3.031381 | 24.0 | 1.018467 |
| w_in_1__0_4 | -0.135690 | 1.161102 | 0.101015 | -2.902407 | 2.339875 | 18.0 | 1.051387 |
| w_in_1__1_0 | 0.071497 | 0.948036 | 0.068116 | -2.057060 | 2.555026 | 67.0 | 1.013077 |
| w_in_1__1_1 | -0.023531 | 0.901718 | 0.072519 | -2.280693 | 2.076487 | 81.0 | 1.000335 |
| w_in_1__1_2 | 0.053893 | 1.127319 | 0.087329 | -2.456869 | 2.609779 | 67.0 | 1.008521 |
| w_in_1__1_3 | 0.047101 | 0.900319 | 0.075818 | -2.516146 | 1.791953 | 12.0 | 1.055726 |
| w_in_1__1_4 | -0.035805 | 0.962708 | 0.082209 | -2.360810 | 2.205260 | 47.0 | 1.000899 |
| w_1_2__0_0 | 0.045259 | 1.230785 | 0.044207 | -2.419610 | 2.257352 | 564.0 | 1.003747 |
| w_1_2__0_1 | 0.041488 | 1.301054 | 0.055290 | -2.277383 | 2.743031 | 446.0 | 0.999899 |
| w_1_2__0_2 | 0.125124 | 1.280967 | 0.046201 | -2.312125 | 2.697887 | 566.0 | 0.999813 |
| w_1_2__0_3 | -0.028414 | 1.304735 | 0.050443 | -2.587809 | 2.428393 | 538.0 | 1.000262 |
| w_1_2__0_4 | 0.001644 | 1.287256 | 0.051705 | -2.583537 | 2.315840 | 448.0 | 1.000342 |
| w_1_2__1_0 | -0.004406 | 1.205375 | 0.041829 | -2.514428 | 2.244782 | 746.0 | 0.999793 |
| w_1_2__1_1 | 0.121821 | 1.251840 | 0.050935 | -2.261252 | 2.517510 | 518.0 | 1.000542 |
| w_1_2__1_2 | -0.008304 | 1.254002 | 0.051344 | -2.213697 | 2.390261 | 498.0 | 1.000063 |
| w_1_2__1_3 | -0.005456 | 1.291233 | 0.048944 | -2.536668 | 2.415580 | 638.0 | 0.999986 |
| w_1_2__1_4 | -0.057718 | 1.277334 | 0.052935 | -2.423612 | 2.380413 | 473.0 | 1.006059 |
| w_1_2__2_0 | -0.019780 | 1.189632 | 0.047975 | -2.274943 | 2.288784 | 561.0 | 0.999921 |
| w_1_2__2_1 | -0.064628 | 1.254670 | 0.054349 | -2.402784 | 2.431458 | 416.0 | 1.000838 |
| w_1_2__2_2 | 0.078829 | 1.258498 | 0.055981 | -2.252705 | 2.592491 | 371.0 | 1.004758 |
| w_1_2__2_3 | -0.048391 | 1.272118 | 0.044732 | -2.434831 | 2.407843 | 625.0 | 1.001006 |
| w_1_2__2_4 | -0.018019 | 1.240764 | 0.056564 | -2.332373 | 2.334165 | 389.0 | 1.000648 |
| w_1_2__3_0 | -0.011157 | 1.239160 | 0.038526 | -2.365355 | 2.310785 | 902.0 | 0.999805 |
| w_1_2__3_1 | 0.046428 | 1.260380 | 0.050470 | -2.314920 | 2.407944 | 536.0 | 0.999840 |
| w_1_2__3_2 | -0.078094 | 1.292863 | 0.051612 | -2.612755 | 2.369275 | 488.0 | 1.002045 |
| w_1_2__3_3 | 0.018767 | 1.302577 | 0.049790 | -2.517321 | 2.450889 | 381.0 | 1.005646 |
| w_1_2__3_4 | 0.047618 | 1.268120 | 0.052708 | -2.293177 | 2.450042 | 499.0 | 1.000193 |
| w_1_2__4_0 | -0.024577 | 1.280421 | 0.051886 | -2.530172 | 2.461077 | 634.0 | 1.000493 |
| w_1_2__4_1 | -0.015574 | 1.292227 | 0.051797 | -2.667592 | 2.328790 | 455.0 | 1.000200 |
| w_1_2__4_2 | -0.020678 | 1.314246 | 0.051867 | -2.589785 | 2.605920 | 494.0 | 1.004190 |
| w_1_2__4_3 | -0.024291 | 1.278493 | 0.047599 | -2.407167 | 2.504326 | 666.0 | 0.999903 |
| w_1_2__4_4 | -0.005184 | 1.287306 | 0.053009 | -2.486049 | 2.611267 | 414.0 | 0.999980 |
| w_2_out__0 | 0.156560 | 2.219129 | 0.105795 | -4.386398 | 4.350683 | 437.0 | 1.000577 |
| w_2_out__1 | 0.223283 | 2.321585 | 0.117838 | -3.916271 | 5.231669 | 206.0 | 1.002508 |
| w_2_out__2 | -0.082721 | 2.400420 | 0.118276 | -4.787125 | 4.424813 | 283.0 | 0.999791 |
| w_2_out__3 | -0.388788 | 2.341725 | 0.110378 | -5.037902 | 4.127480 | 332.0 | 1.009560 |
| w_2_out__4 | -0.067230 | 2.405774 | 0.133776 | -4.656133 | 4.642663 | 240.0 | 1.000985 |
with neural_network:
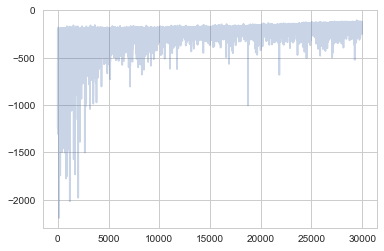
inference = pm.ADVI()
approx = pm.fit(n=30000, method=inference)
Average Loss = 151.75: 100%|██████████| 30000/30000 [00:28<00:00, 1057.53it/s]
Finished [100%]: Average Loss = 151.75
advitrace = approx.sample(draws=5000)
pm.summary(advitrace)
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | |
|---|---|---|---|---|---|
| w_in_1__0_0 | -0.521386 | 0.112502 | 0.001786 | -0.741013 | -0.297054 |
| w_in_1__0_1 | 0.122723 | 0.319251 | 0.004560 | -0.504744 | 0.743053 |
| w_in_1__0_2 | -0.543037 | 0.113075 | 0.001731 | -0.769624 | -0.328908 |
| w_in_1__0_3 | 3.255195 | 0.487644 | 0.006504 | 2.279137 | 4.182791 |
| w_in_1__0_4 | -0.464174 | 0.162645 | 0.002485 | -0.789237 | -0.154705 |
| w_in_1__1_0 | 0.362184 | 0.177318 | 0.002432 | 0.008508 | 0.706695 |
| w_in_1__1_1 | -0.153209 | 0.440645 | 0.006077 | -0.998433 | 0.710622 |
| w_in_1__1_2 | 0.328326 | 0.182822 | 0.002778 | -0.036471 | 0.671428 |
| w_in_1__1_3 | 0.814828 | 0.332562 | 0.004819 | 0.187650 | 1.495967 |
| w_in_1__1_4 | 0.262358 | 0.236041 | 0.003509 | -0.200934 | 0.738899 |
| w_1_2__0_0 | 0.430823 | 0.900179 | 0.012896 | -1.306313 | 2.182824 |
| w_1_2__0_1 | 0.159472 | 1.001399 | 0.015379 | -1.865583 | 2.044132 |
| w_1_2__0_2 | 1.769050 | 0.488465 | 0.006968 | 0.793287 | 2.708693 |
| w_1_2__0_3 | -0.798432 | 0.219366 | 0.002937 | -1.225897 | -0.375460 |
| w_1_2__0_4 | -0.138738 | 1.058936 | 0.015063 | -2.161605 | 1.937199 |
| w_1_2__1_0 | -0.014915 | 0.998757 | 0.015708 | -1.996569 | 1.954171 |
| w_1_2__1_1 | -0.112639 | 1.036376 | 0.014671 | -2.166837 | 1.896193 |
| w_1_2__1_2 | -0.279527 | 0.607058 | 0.007500 | -1.462639 | 0.905531 |
| w_1_2__1_3 | 0.030542 | 0.262629 | 0.003622 | -0.449362 | 0.566730 |
| w_1_2__1_4 | 0.033081 | 1.031896 | 0.014412 | -1.996529 | 2.026740 |
| w_1_2__2_0 | 0.698759 | 0.894654 | 0.013301 | -1.058448 | 2.480351 |
| w_1_2__2_1 | 0.075845 | 0.993218 | 0.014997 | -1.837229 | 2.087505 |
| w_1_2__2_2 | 0.227468 | 0.470235 | 0.006694 | -0.692072 | 1.136107 |
| w_1_2__2_3 | -1.266305 | 0.213226 | 0.003163 | -1.653136 | -0.825669 |
| w_1_2__2_4 | -0.140237 | 1.001324 | 0.014957 | -2.069265 | 1.830847 |
| w_1_2__3_0 | 0.697528 | 0.698237 | 0.009634 | -0.619907 | 2.115031 |
| w_1_2__3_1 | 0.260246 | 0.865400 | 0.012721 | -1.346997 | 1.989603 |
| w_1_2__3_2 | 1.164568 | 0.346030 | 0.004961 | 0.499555 | 1.842212 |
| w_1_2__3_3 | -1.060768 | 0.125721 | 0.001927 | -1.293945 | -0.800757 |
| w_1_2__3_4 | -0.395368 | 0.913273 | 0.013130 | -2.218135 | 1.333269 |
| w_1_2__4_0 | 0.021826 | 0.933852 | 0.013489 | -1.863657 | 1.834411 |
| w_1_2__4_1 | 0.042679 | 1.048042 | 0.015151 | -2.087779 | 2.004247 |
| w_1_2__4_2 | 0.582934 | 0.556188 | 0.007582 | -0.457234 | 1.709272 |
| w_1_2__4_3 | -0.659373 | 0.240979 | 0.003342 | -1.121006 | -0.194694 |
| w_1_2__4_4 | -0.121137 | 1.025468 | 0.013284 | -2.159029 | 1.859368 |
| w_2_out__0 | -0.312281 | 0.265692 | 0.003796 | -0.832638 | 0.205428 |
| w_2_out__1 | -0.076431 | 0.253095 | 0.003764 | -0.557819 | 0.428869 |
| w_2_out__2 | -1.139659 | 0.268075 | 0.003511 | -1.672406 | -0.614689 |
| w_2_out__3 | 3.192447 | 0.274850 | 0.004289 | 2.655092 | 3.718204 |
| w_2_out__4 | 0.112249 | 0.257997 | 0.003784 | -0.414541 | 0.584599 |
plt.plot(-inference.hist, alpha=.3)
[<matplotlib.lines.Line2D at 0x121ced550>]
ann_input.set_value(X_test)
ann_output.set_value(Y_test)
with neural_network:
ppc = pm.sample_ppc(advitrace, samples=1000)
100%|██████████| 1000/1000 [00:00<00:00, 1593.05it/s]
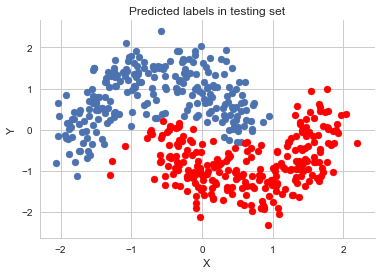
pred = ppc['out'].mean(axis=0) > 0.5
fig, ax = plt.subplots()
ax.scatter(X_test[pred==0, 0], X_test[pred==0, 1])
ax.scatter(X_test[pred==1, 0], X_test[pred==1, 1], color='r')
sns.despine()
ax.set(title='Predicted labels in testing set', xlabel='X', ylabel='Y');
print('Accuracy = {}%'.format((Y_test == pred).mean() * 100))
Accuracy = 95.19999999999999%
grid = pm.floatX(np.mgrid[-3:3:100j,-3:3:100j])
grid_2d = grid.reshape(2, -1).T
dummy_out = np.ones(grid.shape[1], dtype=np.int8)
ann_input.set_value(grid_2d)
ann_output.set_value(dummy_out)
with neural_network:
ppc_grid = pm.sample_ppc(advitrace ,500)
100%|██████████| 500/500 [00:02<00:00, 227.28it/s]
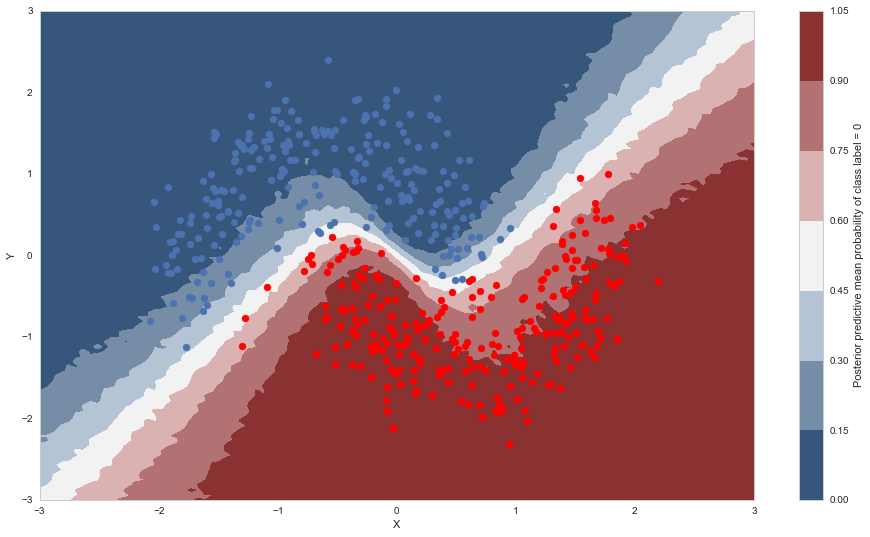
cmap = sns.diverging_palette(250, 12, s=85, l=25, as_cmap=True)
fig, ax = plt.subplots(figsize=(16, 9))
contour = ax.contourf(grid[0], grid[1], ppc_grid['out'].mean(axis=0).reshape(100, 100), cmap=cmap)
ax.scatter(X_test[pred==0, 0], X_test[pred==0, 1])
ax.scatter(X_test[pred==1, 0], X_test[pred==1, 1], color='r')
cbar = plt.colorbar(contour, ax=ax)
_ = ax.set(xlim=(-3, 3), ylim=(-3, 3), xlabel='X', ylabel='Y');
cbar.ax.set_ylabel('Posterior predictive mean probability of class label = 0');
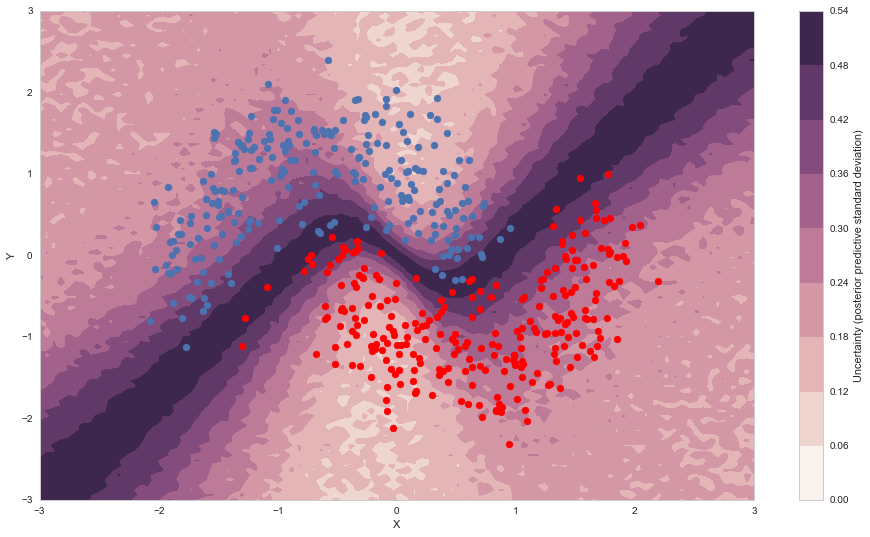
cmap = sns.cubehelix_palette(light=1, as_cmap=True)
fig, ax = plt.subplots(figsize=(16, 9))
contour = ax.contourf(grid[0], grid[1], ppc_grid['out'].std(axis=0).reshape(100, 100), cmap=cmap)
ax.scatter(X_test[pred==0, 0], X_test[pred==0, 1])
ax.scatter(X_test[pred==1, 0], X_test[pred==1, 1], color='r')
cbar = plt.colorbar(contour, ax=ax)
_ = ax.set(xlim=(-3, 3), ylim=(-3, 3), xlabel='X', ylabel='Y');
cbar.ax.set_ylabel('Uncertainty (posterior predictive standard deviation)');
minibatch_x = pm.Minibatch(X_train, batch_size=50)
minibatch_y = pm.Minibatch(Y_train, batch_size=50)
neural_network_minibatch = construct_nn(minibatch_x, minibatch_y)
with neural_network_minibatch:
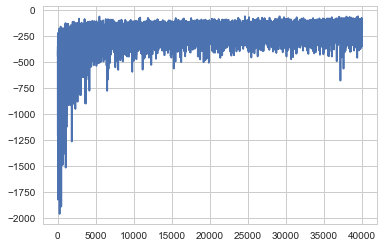
approx_mb = pm.fit(40000, method=pm.ADVI())
Average Loss = 162.17: 100%|██████████| 40000/40000 [00:28<00:00, 1425.03it/s]
Finished [100%]: Average Loss = 162.06
plt.plot(-approx_mb.hist)
[<matplotlib.lines.Line2D at 0x120b2fa58>]